
Introduction
Hi, welcome to my first blog post. This post is the first one in a series of many that will follow.
Who is Tortoise and who is Hare?
Well, In many books about Apache Spark that I was reading, I didn’t found a clear idea of the performance of dataframes compared to the datasets. In this blog post, we will debunk that mystery and show some concrete results and insights regarding this matter.
Two brothers from the same mother
To prepare ourselves for a deep dive into this matter we need to get familiar with the basic concepts of these two API’s.
Dataframe API
Dataframe API is nothing more than data organized in named columns. One good example is the table in a relational database. It’s an untyped version of Datasets i.e. Dataset[Row]. We could say that Dataframe is one step ahead of RDD (resilient distributed dataset) because it provides memory management and an optimized execution plan. This is a famous project called Tungsten which introduced off-heap memory and bypassed the overhead of the JVM object model and garbage collection. The off-heap memory is the memory that doesn’t belong to JVM, the memory that you can allocate and deallocate at your own will. The biggest strength of this API is also the fact that during deserialization, the byte file is converted directly to Java byte code and then executed directly on the Java interpreter.
Dataset API
While the dataframe is untyped the Dataset API provides a type-safe object-oriented programming interface. Dataset doesn’t use. They offer compile-time type safety, which means that you can avoid some runtime errors in comparison to Dataframe API. Their memory is bound to the JVM. This API also enjoys the benefits of Spark SQL’s optimized execution engine.
These two APIs are fundamentally the same except in the fact of how they manage their memory. In the sections below, we will expose some useful insights on which one is more performant and when to use one or another API.
Who runs at the speed of light?
I tested everything locally with a local spark cluster in standalone mode. I took this dataset from Kaggle for benchmarking. 2018 year from this dataset. I made chunks from it from 500K records to 2M in incremental chunks of 250K.
In the figure below, you can see the results of the test.
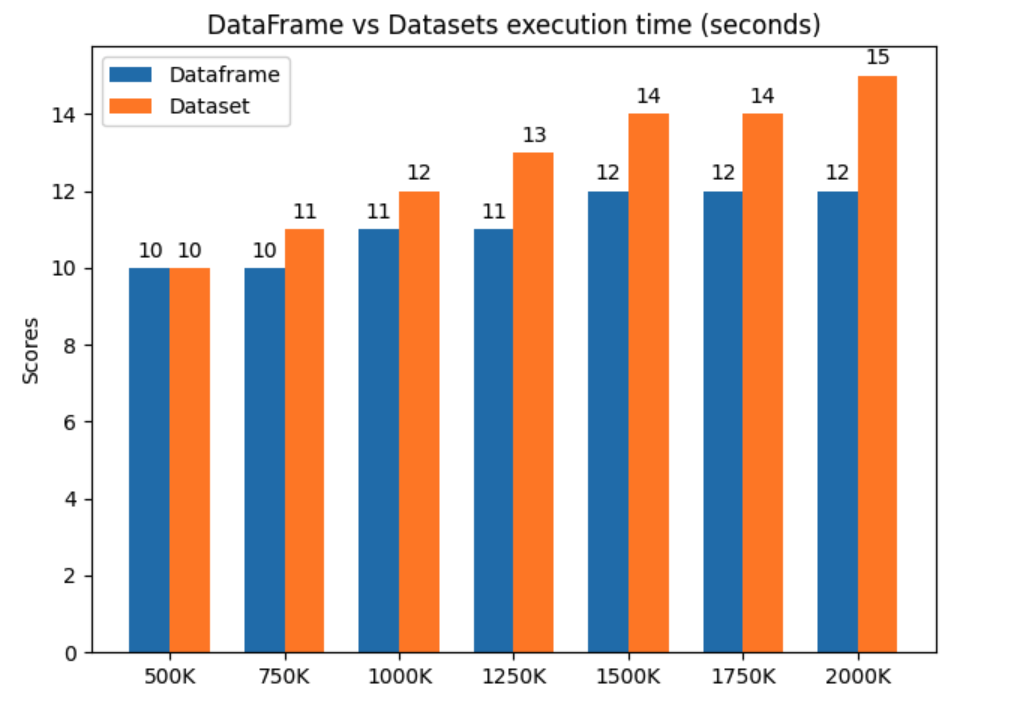
On this link you can find the code for this example.
In this example, we can see that on 2M records we have a 20% improvement over the dataset. Please keep in mind that this test is ultra simple we just read the CSV file and then we group and sum, I’m pretty much convinced that improvement in time would be even more than 20% in execution time on large scale applications.
Dataframe API will be the most performant solution because it avoids garbage collection and works directly on binary data which means that we also don’t have serialization of objects which is a really heavy operation when using datasets, a lot of time is spent on this operation. Whenever the data is traveling from node to node you will have serialization. Imagine now the situation when you have a huge app and you are doing a lot of stuff that causes data to travel around the cluster for at least let’s say 3 times. 3 times 20% you already have 60% improvement in performance of your job.
Another big problem with Java objects is that they have a big memory overhead. For example, to store a simple AAAA string that would take 4 bytes to store in UTF-8 encoding, Java will pack it in ~48 bytes in total. The characters themselves each will use 2 bytes with a UTF-16 encoding, 12 bytes would be spent on the header and the other 8 bytes are used for hash code. To facilitate common workloads we will make a trade-off for a larger memory overhead. If you use Java Object Layout tool you will get the following output:
GC will work well when he’s able to predict the lifecycle of transient objects but it will fail short if some transient objects spill into the old generation. Since this approach is based on heuristics and estimation squeezing out the performance from JVM would take dark arts and dozens of parameters to teach JVM about the life cycle of objects.
To fuel up the performance of the dataframe Project Tungsten uses sun.misc.Unsafe the functionality provided by JVM that exposes C-style memory access with explicit allocation, deallocation, and pointer arithmetics.
Off-Heap memory example
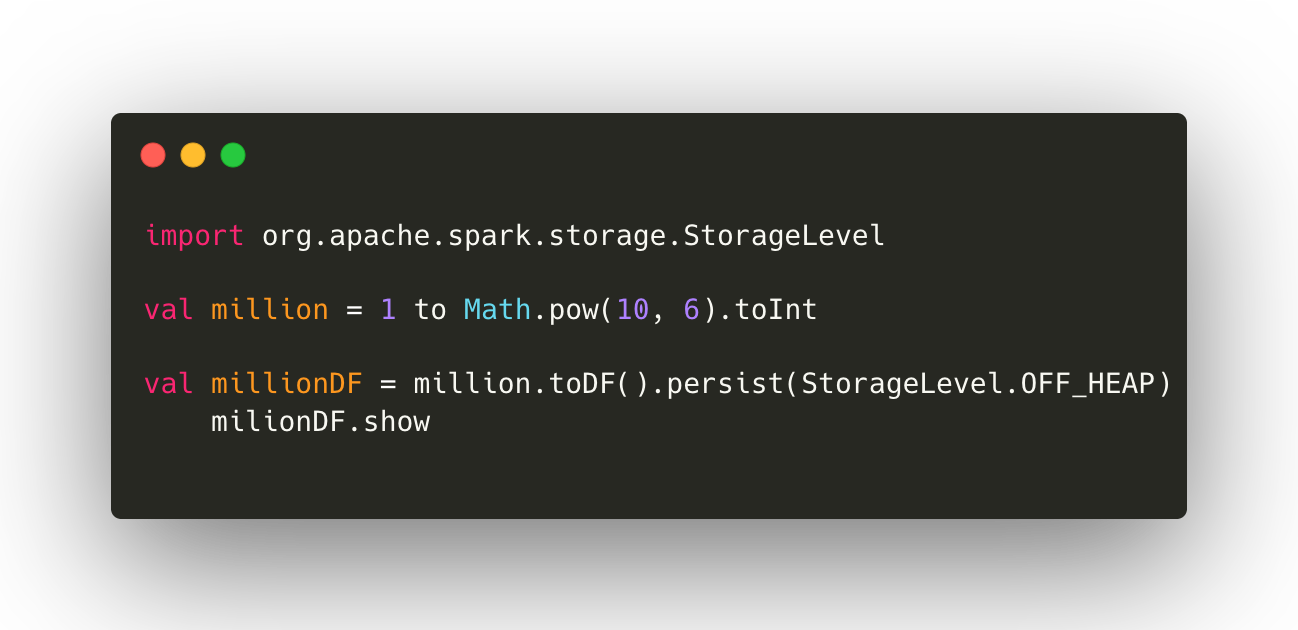
Let’s create a simple example in spark-shell where we can prove that Dataframe is not using JVM memory (big win).
First, let’s enable off-heap memory in spark-shell by running this command.
| |
Dataframe example
Then we will run this chunk of code.
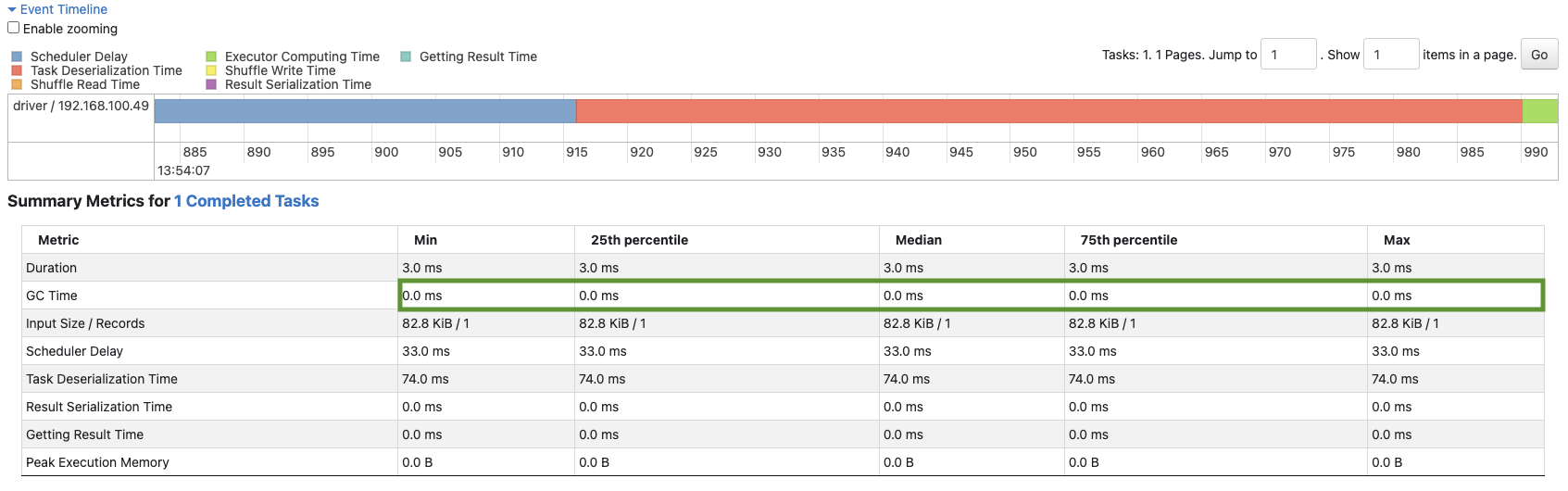
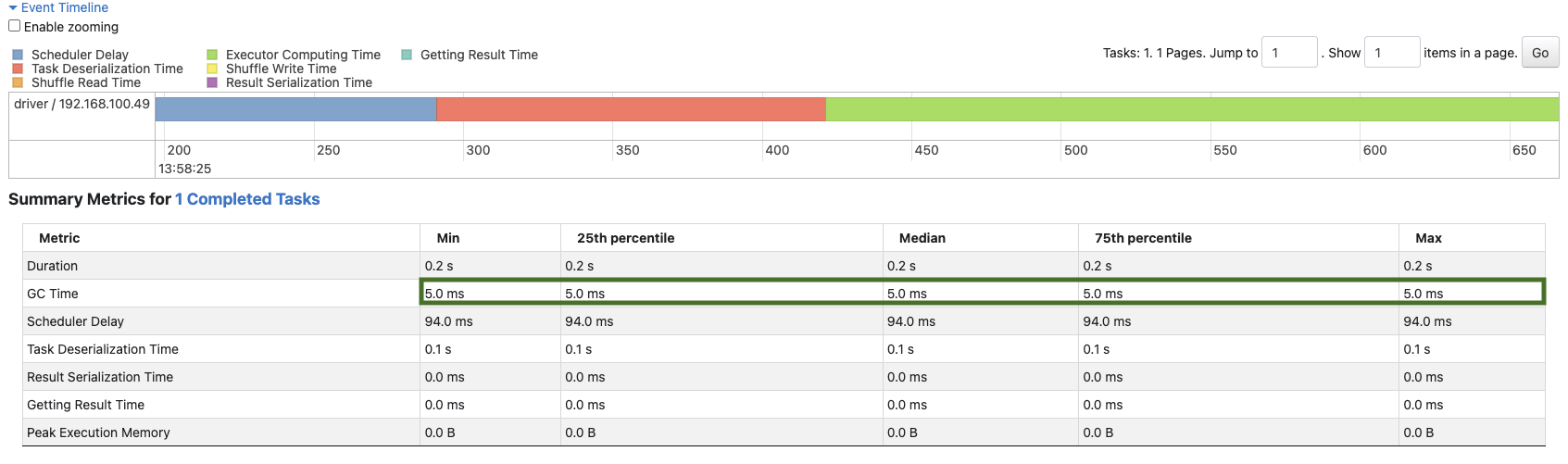
In this image below from the spark web UI, we can see that we are avoiding JVM memory.
Dataset example
Then run this code for dataset.
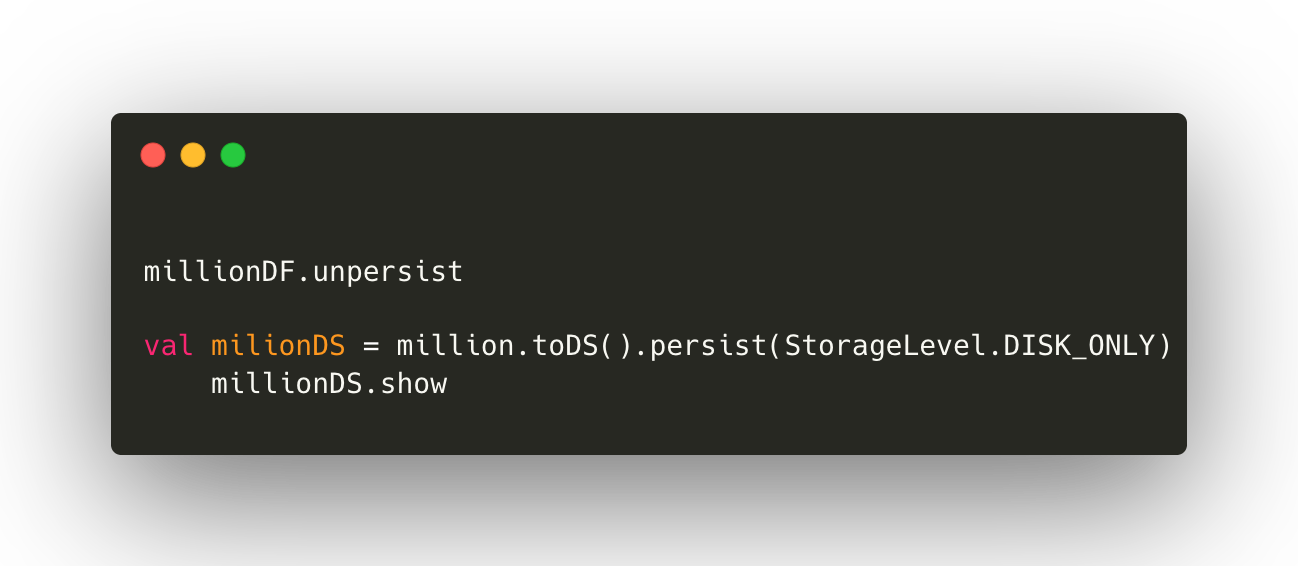
As you can see there is a big difference in GC time.
Final thoughts
If you are ok with the fact that you don’t have compile-time safety then Dataframe API is the most performant solution. If you want compile-time safety and you are willing to pay the trade-off in terms of slower serialization of Java objects and garbage collection overhead, Dataset API is the way to go. There is no perfect tool that doesn’t have its flaws. Chose your weapon wisely :)
Until the next blog post… 👋