
Introduction
Hi there 👋! In this blog post, we will explore why JSON is not suitable as a big data file format. We’ll compare it to the widely used Parquet format and dig deep to demonstrate, through examples, how the JSON format can significantly degrade the performance of your data processing jobs. JSON (JavaScript Object Notation) is a popular and versatile data format, but it has limitations when dealing with large-scale data operations. On the other hand, Parquet, an open-source columnar storage format, has become the go-to choice for big data applications.
Short comparison of JSON vs Parquet
Let’s explore the strengths of both JSON and Parquet file formats by looking at them from a few different perspectives.
Basic Concepts
- JSON
- Text-based, human-readable format
- Originally derived from JavaScript, now language-independent
- Uses key-value pairs and arrays to represent data
- Parquet
- Binary columnar storage format
- Developed by Apache for the Hadoop ecosystem
- Optimized for efficient storage and performance on large datasets
- JSON
Data Structure
- JSON
- Hierarchical structure
- Flexible, schema-less format
- Supports nested data structures
- Each record is self-contained
- Parquet
- Columnar structure
- Strongly typed
- Supports complex nested data structures
- Data is organized by columns rather than rows
- JSON
Storage Efficiency
- JSON
- Typically larger file sizes
- Repetitive field names
- No built-in compression
- Can be compressed externally
- Parquet
- Highly efficient storage
- Built-in compression
- Supports multiple compression codecs (e.g., Snappy, Gzip, LZO)
- Can significantly reduce storage costs for large datasets
- JSON
Read/Write Performance
- JSON
- Fast writes (simple appending of records)
- Slower reads, especially for large datasets
- Requires parsing entire records even when only specific fields are needed
- Parquet
- Slower writes (due to columnar storage and compression)
- Much faster reads, especially for analytical queries
- Supports column pruning and predicate pushdown for efficient querying
- JSON
Schema Evolution
- JSON
- Easily accommodates schema changes
- New fields can be added without affecting existing data
- Parquet
- Supports schema evolution, but with limitations
- Can add new columns or change nullability of existing columns
- Renaming or deleting columns is more challenging
- JSON
Use Cases
- JSON
- Web APIs and data interchange
- Document databases (e.g., MongoDB)
- Logging and event data
- Scenarios requiring human-readable data
- Parquet
- Big data analytics and data warehousing
- Machine learning model training on large datasets
- Business intelligence and reporting systems
- Scenarios prioritizing query performance and storage efficiency
- JSON
Compatibility and Ecosystem Support
- JSON
- Universally supported across programming languages and platforms
- Native support in web browsers and many NoSQL databases
- Easy to work with for developers
- Doesn’t require library for reading and writing
- Parquet
- Strong support in big data ecosystems (Hadoop, Spark, Hive, Impala)
- Strong support in cloud data warehouses (e.g., Amazon Athena, Google BigQuery)
- Requires specific libraries or tools for reading/writing
- JSON
Show time 🌟
In this section, we will showcase all the details about how JSON impacts your Apache Spark job. We will also demonstrate how Apache Spark behaves with the same data written in Parquet on a dataset of ~60GB. We will show all the details using spark web ui
Execution time
When running the code to read a JSON dataset of approximately 60GB of transactions, followed by grouping and summing all transactions by user, the entire job takes 4.7 minutes to execute.
| |

When the same job with the same transactions is run using parquet files, it takes 48 seconds.
See it for yourself 👀

So if you have a job that loads JSON and execution time is 10h the one with Parquet will finish ruffly ~4.8x faster i.e. it would finish in ~2h.
Input data for stage
Ok next stop input data for the stage. Quick recap Spark job is divided into stages, each has many tasks. So stage will be the first receiver of input data, and we want to see the volume for both file types.
Parquet stage input data

JSON stage input data
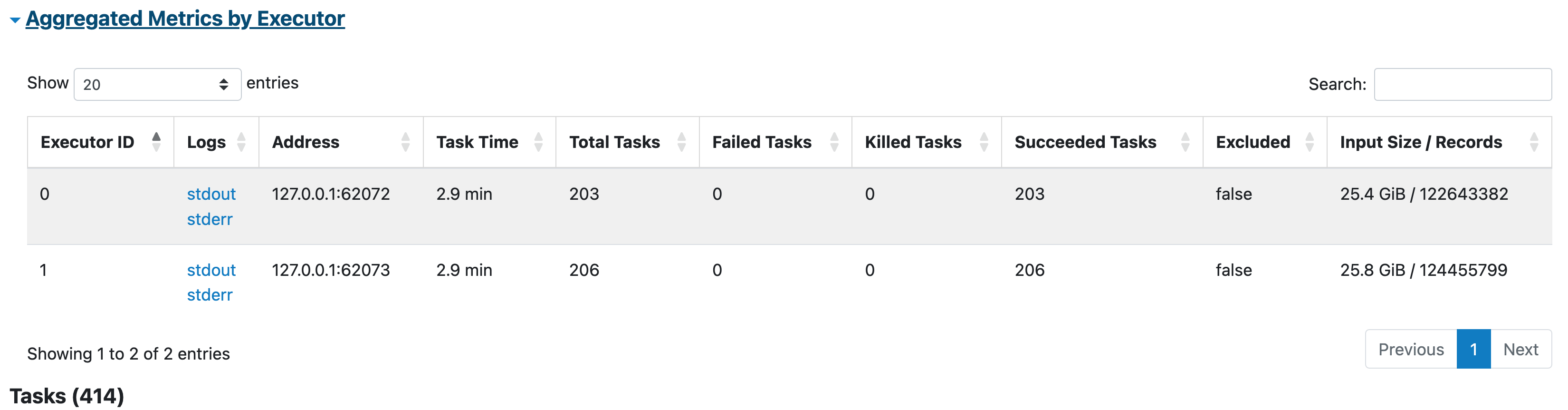
As you can see from the images input data per executor per stage is more than 50% higher. That means also more tasks, more tasks meaning more work for the driver node.
Final thoughts
In this blog post, we have explored the differences between JSON and Parquet file formats in the context of big data processing. While JSON is a popular and flexible format, it has limitations when dealing with large-scale datasets.
Our performance comparison using Apache Spark clearly demonstrates the advantages of using Parquet over JSON for big data workloads. With the same ~60GB dataset, the Spark job using Parquet completed 4.8x faster than the one using JSON. This significant difference in execution time can have a huge impact on the efficiency and cost-effectiveness of your data processing pipelines.
Moreover, Parquet’s columnar storage format and built-in compression result in much smaller file sizes compared to JSON. This not only reduces storage costs but also minimizes the amount of data that needs to be read and processed, further improving performance.
Parquet’s strong typing, schema evolution capabilities, and compatibility with popular big data tools like Hadoop, Spark, and Hive make it an ideal choice for analytics, data warehousing, and machine learning use cases.
In conclusion, while JSON has its place in web APIs and data interchange scenarios, Parquet is the clear winner when it comes to handling large-scale datasets efficiently. By adopting Parquet as your big data file format, you can significantly improve the performance, scalability, and cost-effectiveness of your data processing workflows.