Introduction
Welcome, readers! 📖 In this post, we’ll explore the idea of event source mapping in AWS, with a focus on its implementation and functionality. We’ll zoom-in 🔍 how automatic scaling works and examine the process of consuming messages from Kafka event sources.
Using Lambda to consume records from Kafka
Processing streaming data with traditional server-based technologies and Kafka consumers written in Scala can often introduce unnecessary overhead for simple tasks like creating custom sink consumers to save or delete data based on specific rules. In such scenarios, where complex data processing, joining multiple topics, or a full-fledged streaming application isn’t required, a Python-based Lambda function emerges as a viable alternative.
One of the standout advantages of using AWS Lambda for Kafka data consumption is its streamlined setup process. By simply defining the event source through configuration, AWS handles the underlying infrastructure, eliminating the complexities associated with traditional Scala applications. This contrast between the rapid development and deployment of Lambdas versus the more involved process of building, testing, and deploying Scala applications on servers is a significant factor in favor of Lambdas for many use cases.
What exactly the Event Source Mapping in Lambda is?
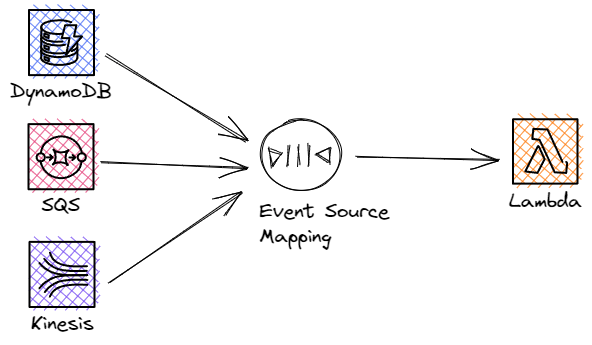
To be able to consume the data from Kafka, you set up something called an Event Source Mapping (ESM) for your Lambda function. This ESM is like a helper that Lambda uses to keep checking Kafka for new messages. It can pick out specific messages and group them together before sending them to your Lambda function to process.
Think of ESM as a message delivery mediator.
It pools and picks up messages from Kafka, bundles them together, and then hands them off to your Lambda function for processing. See the image below.

Scaling and throughput
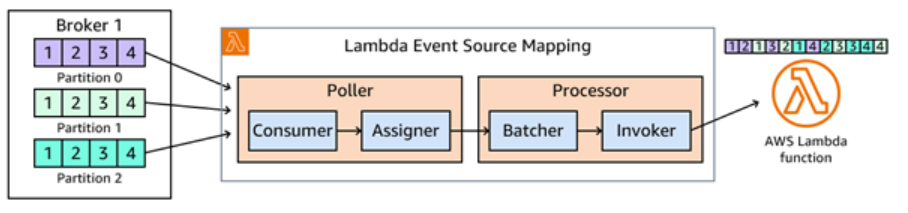
Lambda has helpers called “pollers” that grab data from Kafka. These pollers pass the data to “processors” who bundle it up. When the bundle is full, or it’s been waiting too long, the processor sends it to your Lambda function to be used.
Think of it like a factory. The pollers are the workers collecting raw materials, the processors are the packaging team, and your Lambda function is the machine that turns the packaged materials into a finished product.
When you create lambda event source mapping AWS will create a poller that will poll and consume messages from kafka, it’s basically like a “pre-consumer” of the messages before lambda. The poller also has a component called Assigner whose main function is to forward those messages to the assigned processor for your function. The processor has a batcher component that will group records and then invoke lambda function with the Invoker component.
Scaling logic
How does the internal scaling mechanism work? Well like this.
Here’s a simpler explanation:
Imagine you have a system that receives lots of messages (records) and needs to process them quickly. Here’s how it works:
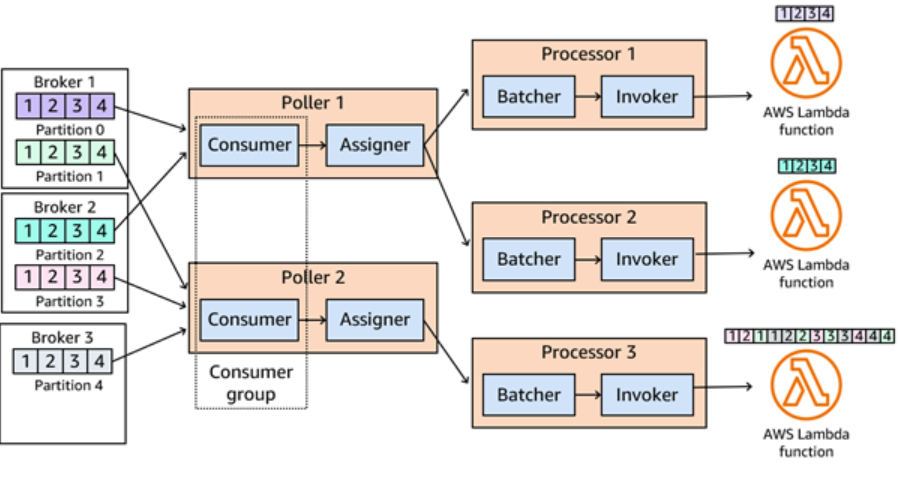
Multiple workers (consumers) receive messages and send them to other workers (processors) to handle.
Each message group (partition) is handled by only one processor to keep things in order.
The system (Lambda) watches how busy everything is and adds or removes workers as needed.
Every minute, it checks if workers are falling behind in processing messages.
If they’re falling behind, the system quickly adds more workers (up to the maximum) within 3 minutes.
The system is also designed to keep workers around longer, especially when there are sudden bursts of messages. This helps process messages faster and reduces delays.
See image bellow to see how scaling works:
Scaling happens automatically and there is nothing you can do about it. This metric dictates will the lambda scale in or out.

So to sum up total number of processors for all pollers is equal to the number of partitions in the topic. This is the case when consumer lag is big and lambda function cannot keep up. In that case topic partitions == poolers == processors == lambda functions invoked. So if you have 10 partitions on maximum scale out you will have 10 pollers, 10 processors and 10 lambdas invoked.
Committing offsets
Whenever lambda finishes with status code 200, the offset will be committed automatically for the kafka topic.
One important thing don’t forget to create a Dead-Letter Queue for all messages that cannot be processed.
How to increase data processing throughput?
Here’s my way of explaining how to improve processing throughput:
- Smart Filtering
Use filters to only process the data you actually need. It’s like sorting your mail and throwing out the junk before you even open it. This saves time and money.
- More Workers
Imagine you’re running a kitchen. If you have more cooks (partitions), you can prepare more meals (process more data) at once. Add more partitions to handle more data simultaneously. More partitions mean more concurrent lambda created to consume those messages.
- Beefier Machines
Sometimes, you need stronger computers, not just more of them. It’s like upgrading from a bicycle to a motorcycle - you’ll get there faster. Give your functions more memory and CPU power for tough jobs.
- Bigger Batches
Instead of washing one dish at a time, fill up the sink and do a whole batch. Processing data in larger chunks can be more efficient, but be careful - waiting to fill a very large batch might slow down the start of your process.
- Spread the Load
The key is finding the right balance for your specific needs. Each method has its pros and cons, so mix and match to find what works best for you.
Final Thoughts
When I can choose which type of kafka event source consumer should I write I would go with a lambda function. No deployment no servers needed for consuming and processing messages. For custom logic, sink lambdas are powerful. The only thing I don’t like is this scaling logic over which I don’t have control their algorithm is a black box.