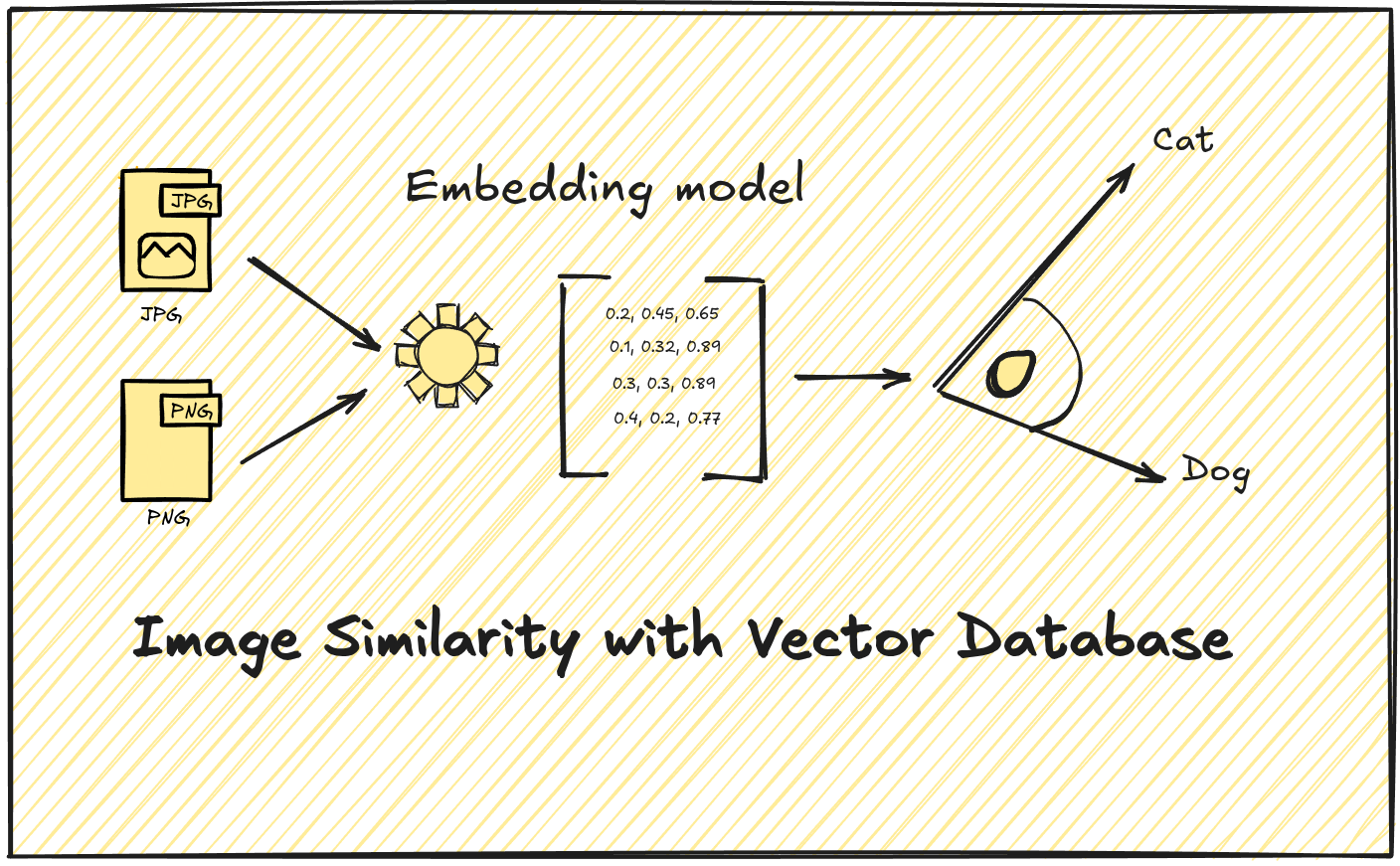
Introduction#
Have you ever wondered how Pinterest finds visually similar images or how Google Photos recognizes faces across thousands of pictures? The technology that powers these features isn’t magic—it’s vector similarity search. Today, modern vector databases make it possible for developers to build these powerful visual search capabilities without needing a PhD in computer vision.
In this post, I’ll guide you through the process of building your own image similarity search engine. We’ll cover everything from understanding vector embeddings to implementing a working solution that can find visually similar images in milliseconds.
Understanding Vector Embeddings for Images#
Before we dive into the implementation details, let’s understand what vector embeddings are and why they’re crucial for image similarity search.
What is vector?#
A vector is a simple mathematical idea that describes something with both a size (how much) and a direction (which way). Think of a vector like an arrow: the length of the arrow shows how big it is, and the way it points shows the direction.
Everyday Example#
Imagine you’re giving someone directions:
“Walk 3 steps forward and 4 steps to the right.”
This instruction can be shown as an arrow from where you start to where you end up. That arrow is a vector: it tells you both how far to go (the magnitude) and which way to go (the direction)
3 steps forward would be the magnitude of a vector and direction would be 4 steps to the right
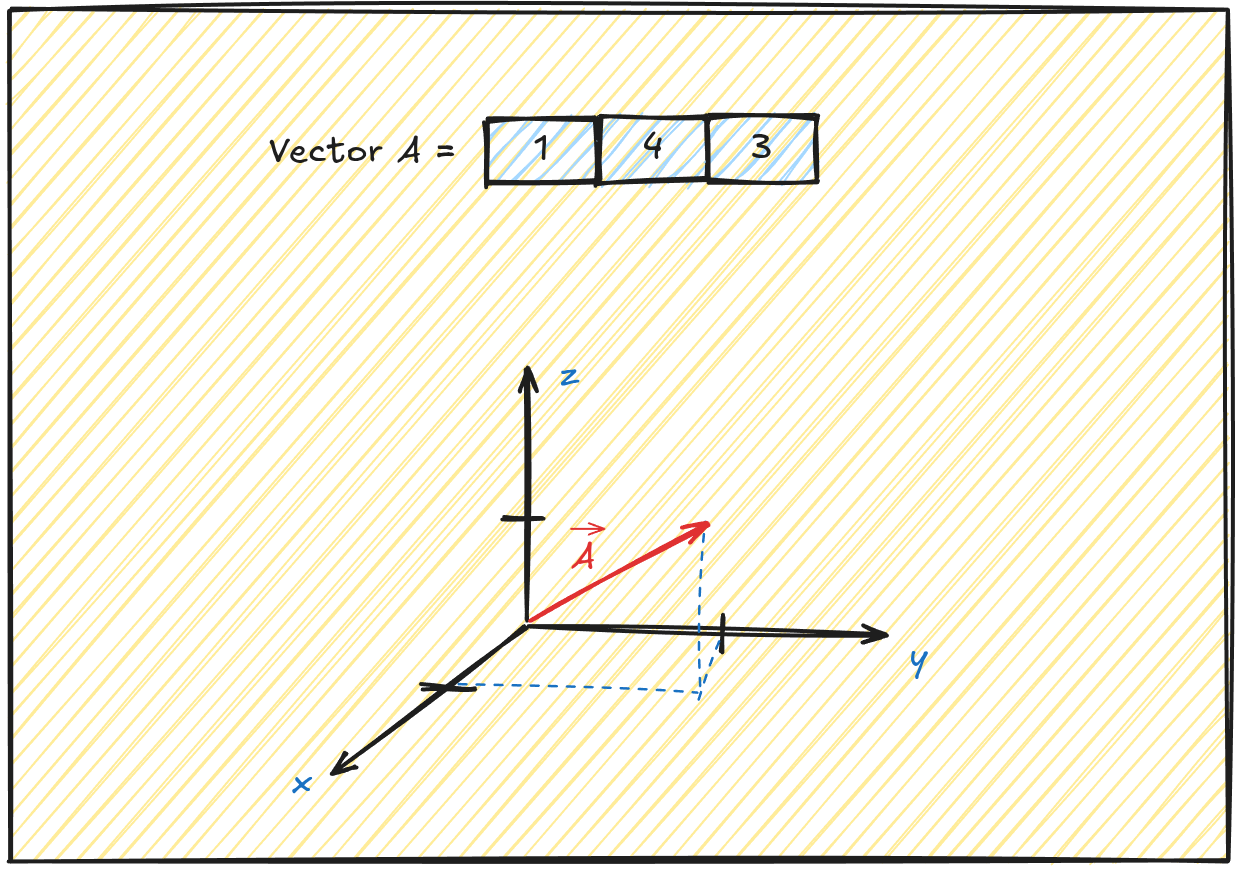
What is dimension of vector?#
Vector dimension is a way to describe how much information is needed to specify a vector, or how many “directions” you can move in that space.
If you look at this image this vector wil have 3 dimensions (1, 4, 3). It can contain as many dimesions as you want. Everything more than 3 dimesions is hard to imagine and plot.
What is vector space?#
Vector space is container of all vectors, imagine this as a bucket for all vectors.
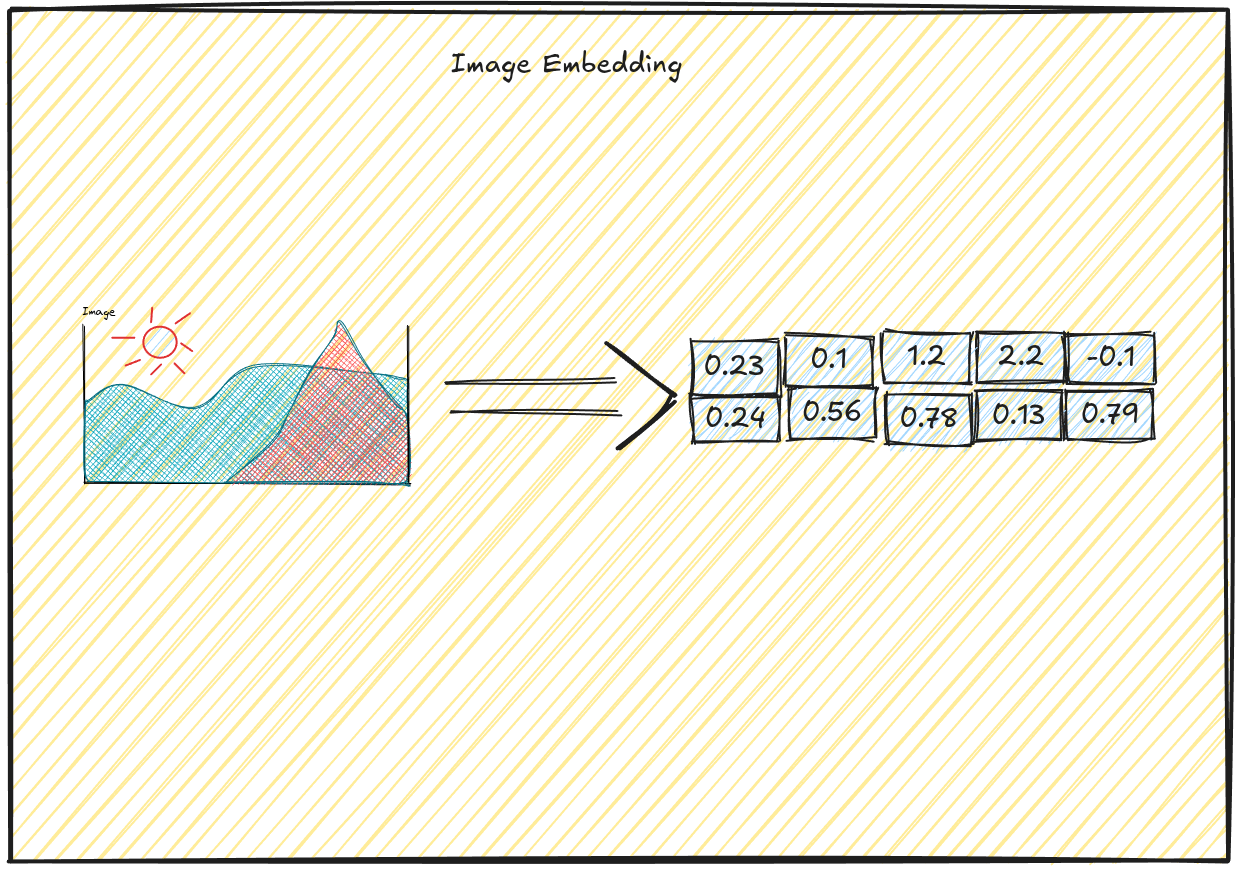
What Are Vector Embeddings?#
Vector embeddings are numerical representations of data in multi-dimensional (vector) space. For images, these embeddings capture visual features like shapes, textures, colors, and objects within a fixed-length vector (typically hundreds or thousands of dimensions).
In simple words, machines aren’t naturally good at understanding data like images, audio, and text. To help them process this information, we convert it into a mathematical form a domain where machines know how to operate effectively and can detect patterns in data.
The beauty of vector embeddings is that similar images will have vectors that are closer to each other in this high-dimensional space. This geometric property allows us to find similar images by measuring the distance between vectors.
Vector Databases: The Engine Behind Similarity Search#
Traditional databases are great for exact matches and range queries, but they fall short when it comes to finding “similar” items in high-dimensional space. This is where vector databases shine.
What Makes Vector Databases Special?#
Vector databases are purpose-built for storing and querying vector embeddings. They implement specialized algorithms like Approximate Nearest Neighbor (ANN) search that can efficiently find the closest vectors to a query vector, even in datasets with millions of entries.
Key features that set vector databases apart:
- Similarity metrics: Support for cosine similarity, Euclidean distance, and other vector comparison methods
- Indexing structures: Advanced indexing like HNSW or IVF that enable sub-linear search times
- Filtering capabilities: Combining vector similarity with metadata filtering
- Scalability: Distributed architecture for handling large collections
Popular Vector Database Options#
Several powerful vector databases have emerged in recent years:
| Database | Key Features ⭐ | 🚀 Best For |
|---|
| Pinecone | Fully managed, serverless 🛠️ | Production deployments 🏭 |
| Milvus | Open-source, highly scalable 🌱 | Self-hosted large-scale applications 🏢 |
| Weaviate | Schema-based, multimodal 🧩 | Complex data relationships 🔗 |
| Qdrant | Simple API, filtering, self-hosted ⚡ | Quick prototyping, startups 🚀 |
Building Your Image Similarity Search Pipeline#
Let’s dive into the practical steps for building an image similarity search system:
Step 1: Image Collection and Preprocessing#
First, you’ll need a collection of images. For this tutorial, let’s assume we have a directory of some images. For this tutorial, I will choose some random wild animals.
1
2
3
4
5
6
7
8
9
10
|
import os
from pathlib import Path
# Define image directory
image_dir = Path("./data/images/")
# Get all image paths
image_paths = [str(f) for f in image_dir.glob("*.jpg")]
print(f"Found {len(image_paths)} images")
|
Step 2: Generating Vector Embeddings#
Next, we’ll generate vector embeddings for all images using resnet50.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
import numpy as np
from tqdm import tqdm
import torch
from torchvision import models, transforms
from PIL import Image
model = models.resnet50(pretrained=True)
# Remove the classification layer to get embeddings
model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval()
# Prepare image transformation
# We are scaling all images and normalizng them
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def get_image_embedding(image_path):
# Load and transform image
img = Image.open(image_path).convert('RGB')
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0)
# Get embedding
# Using already trained model resnet50
with torch.no_grad():
embedding = model(batch_t)
# Flatten to 1D vector and return as numpy array
return embedding.squeeze().cpu().numpy()
# Generate embeddings for all images
embeddings = {}
for img_path in tqdm(image_paths, desc="Generating embeddings"):
try:
# Get the image ID from the filename
img_id = os.path.basename(img_path).split('.')[0]
# Generate embedding
embedding = get_image_embedding(img_path)
embeddings[img_id] = embedding
except Exception as e:
print(f"Error processing {img_path}: {e}")
print(f"Generated embeddings for {len(embeddings)} images")
|
Step 3: Storing Vectors in a Vector Database#
Now, let’s store these embeddings in Qdrant:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
# Initialize Qdrant client - local one
collection_name = "animals"
if not client:
client = QdrantClient(path="./qdrant_data")
# Create a new collection for our image embeddings
vector_size = next(iter(embeddings.values())).shape[0] # Get dimension from first embedding
client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE)
)
# Prepare points for upload
cnt = 1
embedded_images = []
for img_id, embedding in embeddings.items():
cnt+=1
embedded_images.append(PointStruct(
id=cnt,
vector=embedding.tolist(),
payload={"image_path": str(image_dir / f"{img_id}.jpg"), "name": img_id}
))
# Upload in batches
batch_size = 10
for i in range(0, len(points), batch_size):
client.upsert(
collection_name=collection_name,
points=embedded_images[i:i + batch_size]
)
print(f"Uploaded {len(points)} embeddings to Qdrant")
|
Step 4: Creating the Search API#
Let’s create a simple API for searching similar images:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
import nest_asyncio
import uvicorn
import threading
from fastapi import FastAPI, UploadFile, File
from fastapi.middleware.cors import CORSMiddleware
import os
import tempfile
# Apply nest_asyncio to allow running asyncio event loops within Jupyter
nest_asyncio.apply()
# Create the FastAPI app
app = FastAPI()
# Add CORS middleware to allow requests from the Jupyter environment
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.post("/search")
async def search_similar(
file: UploadFile = File(...),
limit: int = 5
):
# Save uploaded file temporarily
with tempfile.NamedTemporaryFile(delete=False, suffix=".jpg") as temp:
temp.write(await file.read())
temp_path = temp.name
try:
# Generate embedding for uploaded image
query_embedding = get_image_embedding(temp_path)
# Search for similar images
search_results = client.search(
collection_name="product_images",
query_vector=query_embedding.tolist(),
limit=limit
)
# Format results
results = []
for res in search_results:
results.append({
"image_id": res.id,
"image_path": res.payload["image_path"],
"similarity": res.score
})
return {"results": results}
finally:
# Clean up
os.unlink(temp_path)
# Function to start the FastAPI server in a separate thread
def run_fastapi(host="127.0.0.1", port=8000):
server = uvicorn.Server(config=uvicorn.Config(app=app, host=host, port=port))
thread = threading.Thread(target=server.run)
thread.daemon = True
thread.start()
print(f"FastAPI running on http://{host}:{port}")
return thread
# Start the server
fastapi_thread = run_fastapi()
# Display URL for testing
from IPython.display import display, HTML
display(HTML('<a href="http://127.0.0.1:8000/docs" target="_blank">Open FastAPI Swagger UI</a>'))
|
Step 5: Building a Simple UI for Image Search#
Finally, let’s create a basic web interface using Streamlit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| import streamlit as st
import requests
from PIL import Image
import io
st.title("Image Similarity Search")
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
if uploaded_file is not None:
# Display the uploaded image
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", width=300)
# Create a copy of the file for sending to the API
bytes_data = io.BytesIO()
image.save(bytes_data, format='JPEG')
bytes_data.seek(0)
# Search for similar images
if st.button("Find Similar Images"):
with st.spinner("Searching..."):
files = {"file": ("image.jpg", bytes_data, "image/jpeg")}
response = requests.post("http://localhost:8000/search", files=files)
if response.status_code == 200:
results = response.json()["results"]
if results:
st.success(f"Found {len(results)} similar images")
# Display results in a grid
cols = st.columns(3)
for i, result in enumerate(results):
img = Image.open(result["image_path"])
cols[i % 3].image(
img,
caption=f"Similarity: {result['similarity']:.2f}",
width=200
)
else:
st.warning("No similar images found")
else:
print(response.text)
st.error("Error searching for similar images")
|
To run streamlit ui run this command in you cli:
1
| streamlit run vector-search-ui.py
|
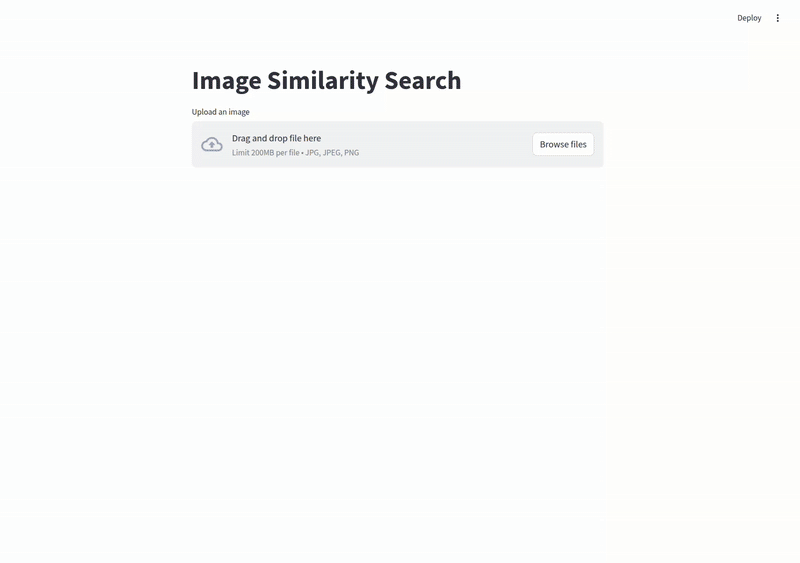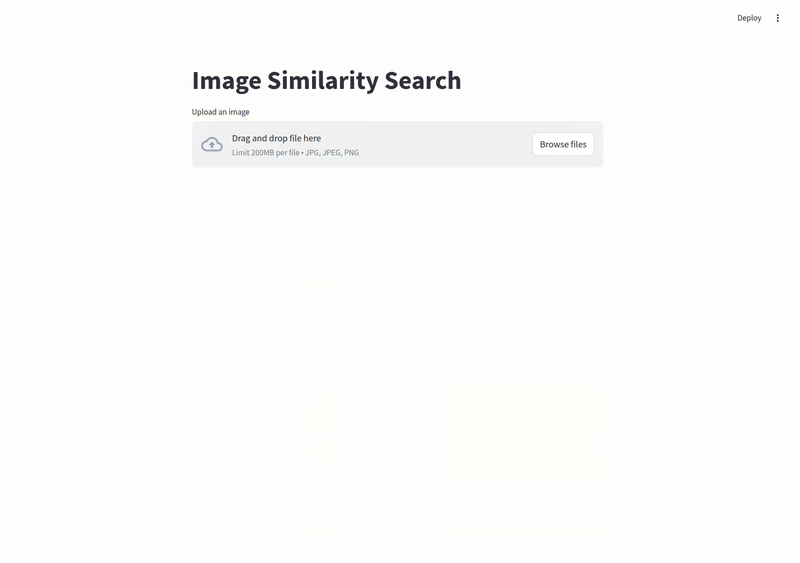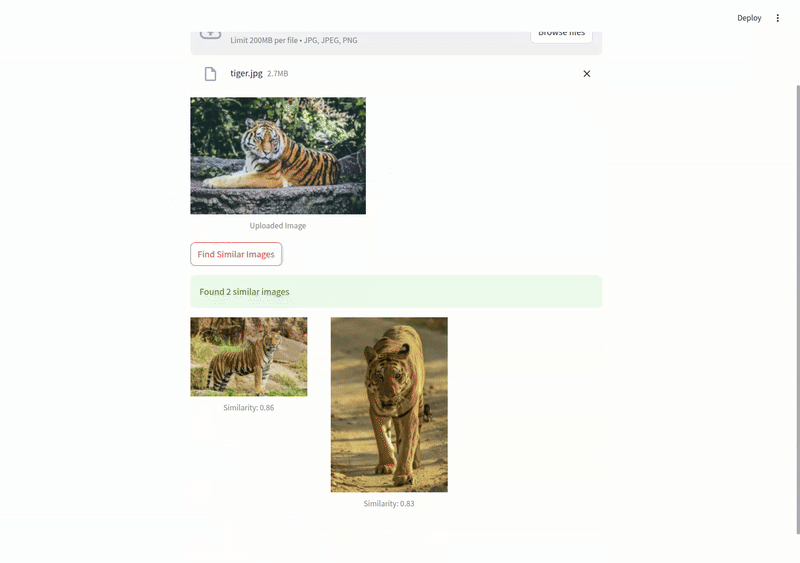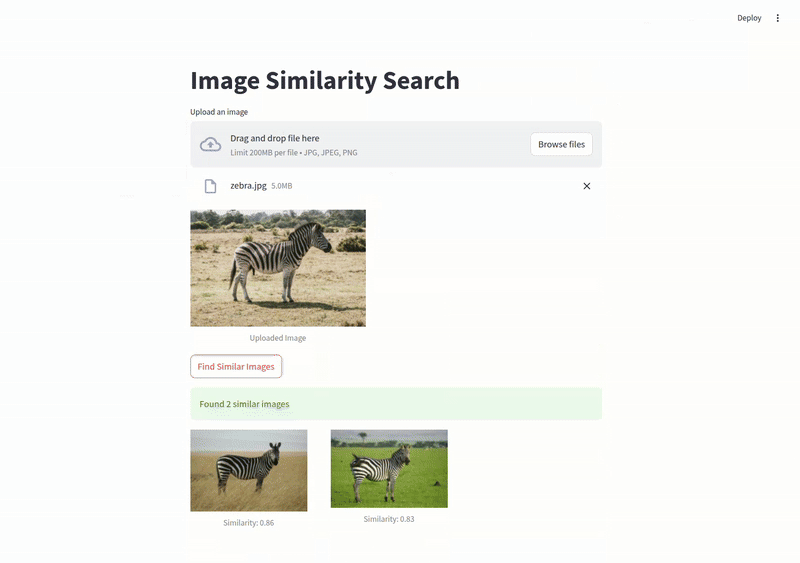
Image similarity in action#
Final Thoughts: Endless Possibilities with Image Similarity Search#
We’ve just scratched the surface of what’s possible with image similarity search.
The combination of modern embedding models and vector databases opens up exciting applications across numerous domains:
E-commerce and Retail#
- Visual product search (“find products that look like this”)
- Style-based recommendations
- Outfit completion suggestions
- Counterfeit detection
Content Moderation#
- Finding similar inappropriate content
- Identifying duplicates or variations of banned material
- Protecting brand assets from unauthorized use
Digital Asset Management#
- Organizing large image libraries by visual similarity
- Eliminating duplicate or near-duplicate images
- Categorizing untagged images based on visual content
Remember that the quality of your search results depends heavily on the quality of your embeddings. For specialized use cases, you might want to fine-tune your embedding model on your specific image domain rather than using a general-purpose pre-trained model like ResNet50
Full example of the code can be found here