
What if I told you that you could run vector searches directly on S3 without spinning up a single database or compute cluster? For years, we’ve been stuck with a painful pipeline: extract data from S3, chunk it, generate embeddings, load everything into OpenSearch or Pinecone, and manage all that infrastructure.
Amazon just changed the game with S3 Vectors – it’s S3 that can do vector math natively, no compute engine required. This means up to 90% cost savings and zero infrastructure management. Let me show you exactly how this works and why it might replace your vector database entirely.
The Old Way: Why Vector Storage Was a Pain 😓
Picture the traditional vector search architecture: Your data sits in S3, then you need an embedding application to chunk and vectorize it, followed by a vector database like OpenSearch or Pinecone, and finally your application queries that database.
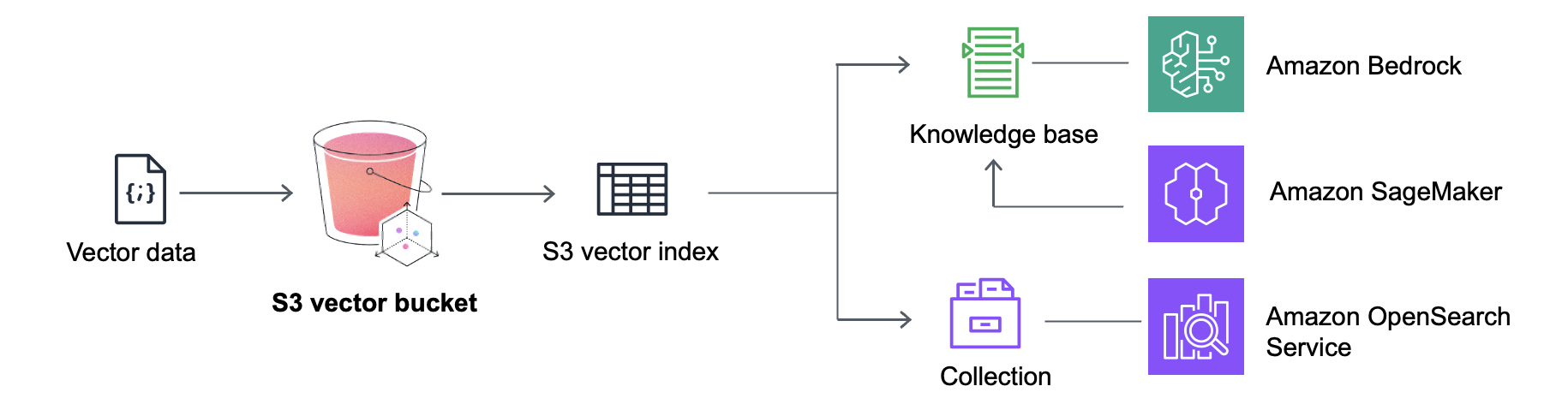
Each step is a potential failure point – managing chunking strategies, handling batch processing, dealing with failed embeddings, and orchestrating everything with Lambda or ECS.
The costs are brutal. OpenSearch runs you $700+/month minimum for a production cluster, plus you’re managing index allocation, shard management, and capacity planning. You’re essentially paying twice – once for S3 storage and again for vector database storage and compute – all just to run similarity searches on data that was already sitting in S3.
Enter S3 Vectors: Storage That Actually Thinks 🧠
S3 Vectors isn’t just another storage option – it’s S3 with built-in vector search capabilities. No separate compute engine, no database cluster, just native vector operations right where your data lives. You create a vector bucket, define vector indexes with dimensions and distance metrics (cosine or euclidean), and start querying with subsecond response times.
The numbers are impressive: each vector bucket supports up to 10,000 indexes, and each index can hold tens of millions of vectors. You can attach metadata to vectors for filtered searches, and S3 automatically optimizes the data structure as your dataset grows. Best part? You only pay for storage and queries – no compute clusters burning money 24/7.
How It Works Under the Hood? ⚙️
Vector buckets are a completely new S3 bucket type with dedicated APIs for vector operations. Unlike traditional buckets that store objects as blobs, vector buckets organize data into vector indexes – think of them as purpose-built structures optimized for similarity search. When you create an index, you specify the vector dimensions (must match your embedding model) and the distance metric.
The real magic happens during queries. S3 Vectors uses approximate nearest neighbor (ANN) algorithms to find similar vectors without scanning the entire dataset. You send a query vector, specify how many results you want (topK), and optionally add metadata filters. S3 handles all the indexing, optimization, and query execution internally – no FAISS libraries, no managing HNSW parameters, just simple API calls.
As you add, update, or delete vectors, S3 automatically rebalances and optimizes the index structure. This means consistent performance whether you have 1,000 or 10 million vectors, without any manual tuning or re-indexing operations.
Practical Implementation: From Zero to Vector Search 💻
First let’s create a bucket.
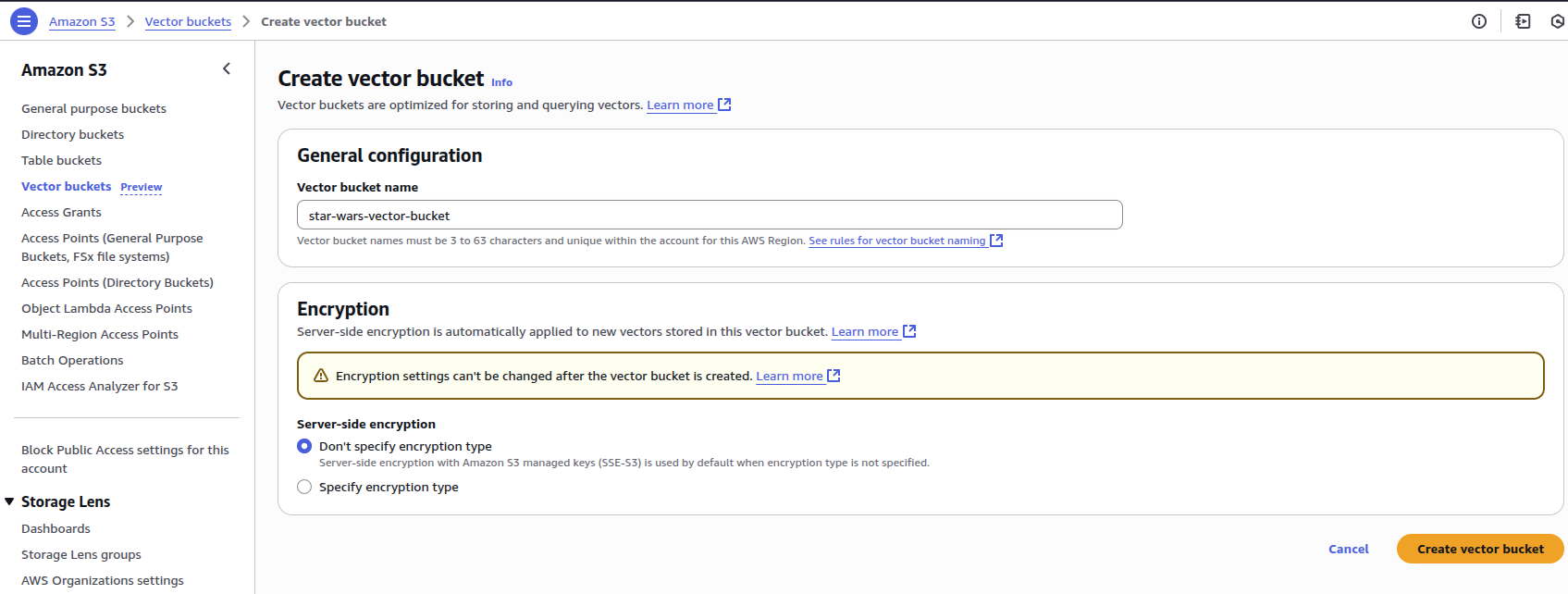
Once created we can then create a vector index and query our data.
Let’s build a simple vector search system. First, create a vector bucket and index:
Generate embeddings using Bedrock and insert them into your index:
| |
Generate embeddings using Bedrock and insert them into your index:
| |
Query your vectors with similarity search:
| |
The Cost Revolution: 90% Savings Isn’t a Typo 💰
Let’s talk real numbers. For 10 million vectors (1536 dimensions each), OpenSearch Serverless costs approximately $1,400/month – that’s $700 for compute units (2 OCUs minimum) plus storage costs. Traditional OpenSearch clusters aren’t much better, starting at $500-700/month for production-ready instances before you even factor in storage and data transfer.
With S3 Vectors, those same 10 million vectors cost roughly $140/month – just storage pricing at S3 rates, no compute charges. You only pay extra when you query, and even then it’s pennies compared to running a cluster 24/7. No more paying for idle compute during off-hours or over-provisioning for peak loads.
For examaple (taken from AWS documentation):
Tier 2 query processing cost = 9.9 million vectors * 5.17 KB/average vector * $0.002/TB * 10 million queries = $953.36
For ~10M vectors and 10M queries per month you will pay roughly $953.36
The hidden savings are equally important: zero infrastructure management, no cluster upgrades, no rebalancing shards, no capacity planning meetings.
Your DevOps team can focus on building features instead of babysitting vector databases. For infrequently queried vectors (think historical data or cold archives), the savings approach 95% compared to keeping everything in a hot OpenSearch cluster.
Integration Superpowers? 🔗
S3 Vectors integrates seamlessly with Amazon Bedrock Knowledge Bases, making RAG applications dead simple. Just point your knowledge base at an S3 vector bucket – no more managing separate vector stores or dealing with sync issues. Your documents, embeddings, and search all live in one place, and Bedrock handles the orchestration automatically.
The OpenSearch integration enables smart tiering strategies. Keep your hot data (frequently queried vectors) in OpenSearch for millisecond latency, while cold data sits cost-effectively in S3 Vectors. When query patterns change, you can export from S3 to OpenSearch with a few clicks – no complex ETL pipelines or re-embedding required.
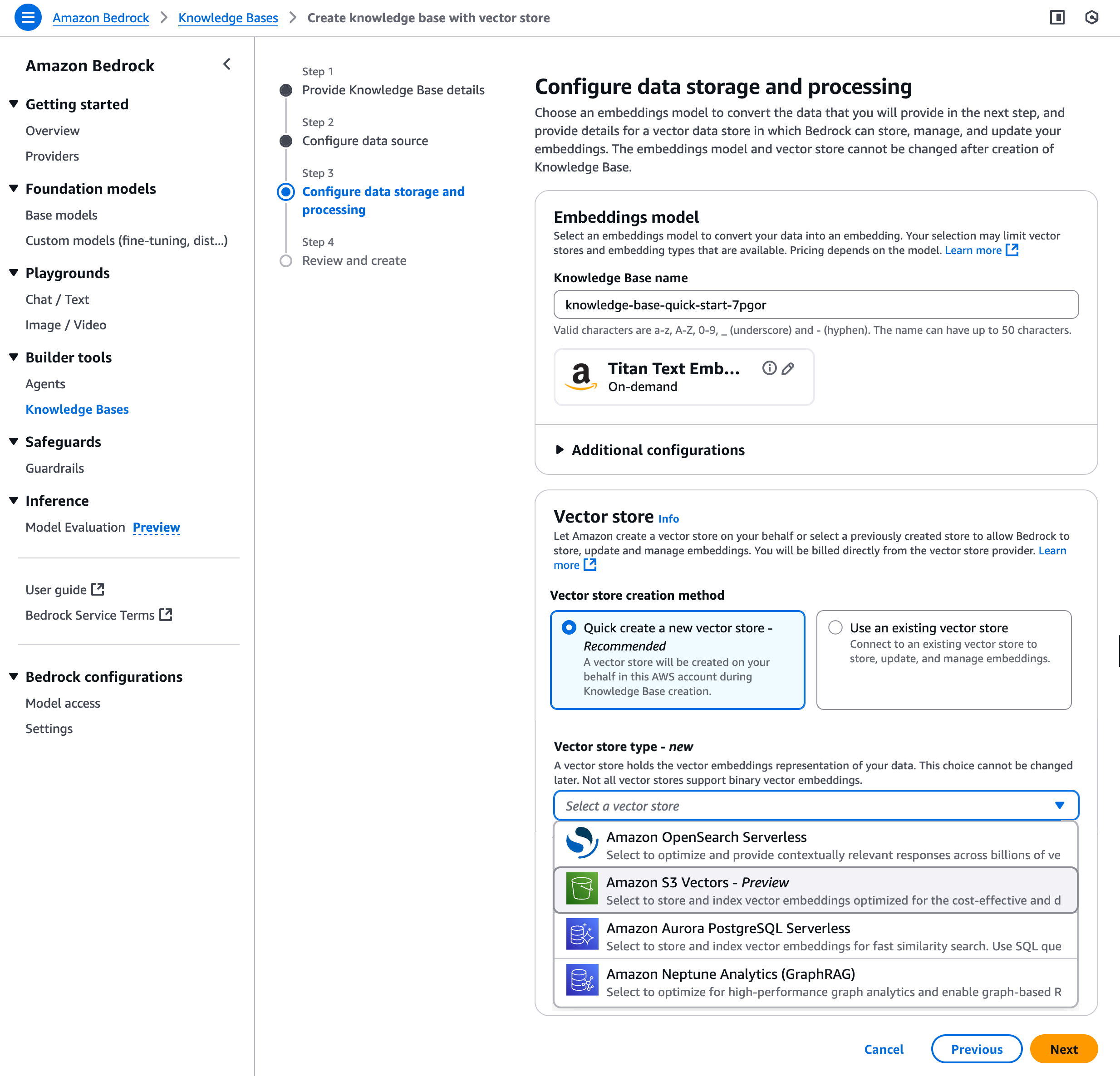
SageMaker Unified Studio users get S3 Vectors as a native option when building generative AI applications. Create knowledge bases, manage vector indexes, and deploy chat agents all from one interface. The integration handles embedding generation, vector storage, and retrieval automatically – you just focus on the application logic.
Limitations and Trade-offs? ⚖️
S3 Vectors is currently in preview with availability in only five regions, so production deployments need to wait. The subsecond query performance is impressive but won’t match OpenSearch’s millisecond latency for real-time applications like autocomplete or live recommendation systems. If you need 100+ queries per second with <10ms response times, you’ll still want a dedicated vector database.
There’s also the feature gap to consider. S3 Vectors handles similarity search well, but lacks advanced capabilities like hybrid search (combining vector and keyword search), complex aggregations, or real-time updates.
The 10,000 indexes per bucket limit might seem generous, but multi-tenant applications with per-customer isolation could hit this ceiling. Additionally, all vectors in an index must have identical dimensions – no mixing different embedding models in the same index.
Conclusion 🎯
S3 Vectors represents a fundamental shift in how we think about vector storage. For most RAG applications, document search systems, and AI workloads that don’t need millisecond latency, the traditional vector database is now unnecessary overhead.
You get 90% cost savings, zero infrastructure management, and seamless AWS integrations – all with the reliability of S3.
The sweet spot is clear: use S3 Vectors for large-scale vector storage, cold data, and cost-sensitive workloads. Keep OpenSearch or Pinecone only for your truly real-time, high-QPS requirements.
As this service moves from preview to GA and adds more features, expect to see vector databases become specialty tools rather than default choices.
Want to try it yourself? S3 Vectors is available in preview in US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Frankfurt), and Asia Pacific (Sydney). Start with a small proof of concept – migrate some cold vectors from your existing database and compare the costs.
The future of vector storage just got a lot simpler – and cheaper.