Introduction
The data warehouse landscape is experiencing a tectonic shift. After decades of dominance by traditional vendor-locked solutions, a new way of thinking is emerging: data warehouses built on open table formats. This architectural approach isn’t just another incremental improvement—it represents a fundamental reimagining of how organizations store, manage, and analyze their critical data assets.
Open table formats like Apache Iceberg, Delta Lake, and Apache Hudi are transforming what’s possible in data warehousing. By decoupling storage from compute and leveraging cloud-native technologies, these formats enable data architectures that are more flexible, cost-effective, and powerful than their traditional counterparts.
In my years working at various companies I’ve witnessed firsthand how legacy data warehouse architectures strain under modern data volumes and velocity especially under the new wave of AI. The limitations become increasingly apparent: rigid schemas, costly scaling, vendor lock-in, and separation between analytical and operational workloads.
This blog post explores why data warehouses backed by open table formats aren’t just an alternative to traditional data warehouses—they’re poised to replace them entirely.
Let’s start by exploring how we got here, looking at the evolution of data warehousing and the limitations that have set the stage for this revolution.
The Evolution of Data Warehousing
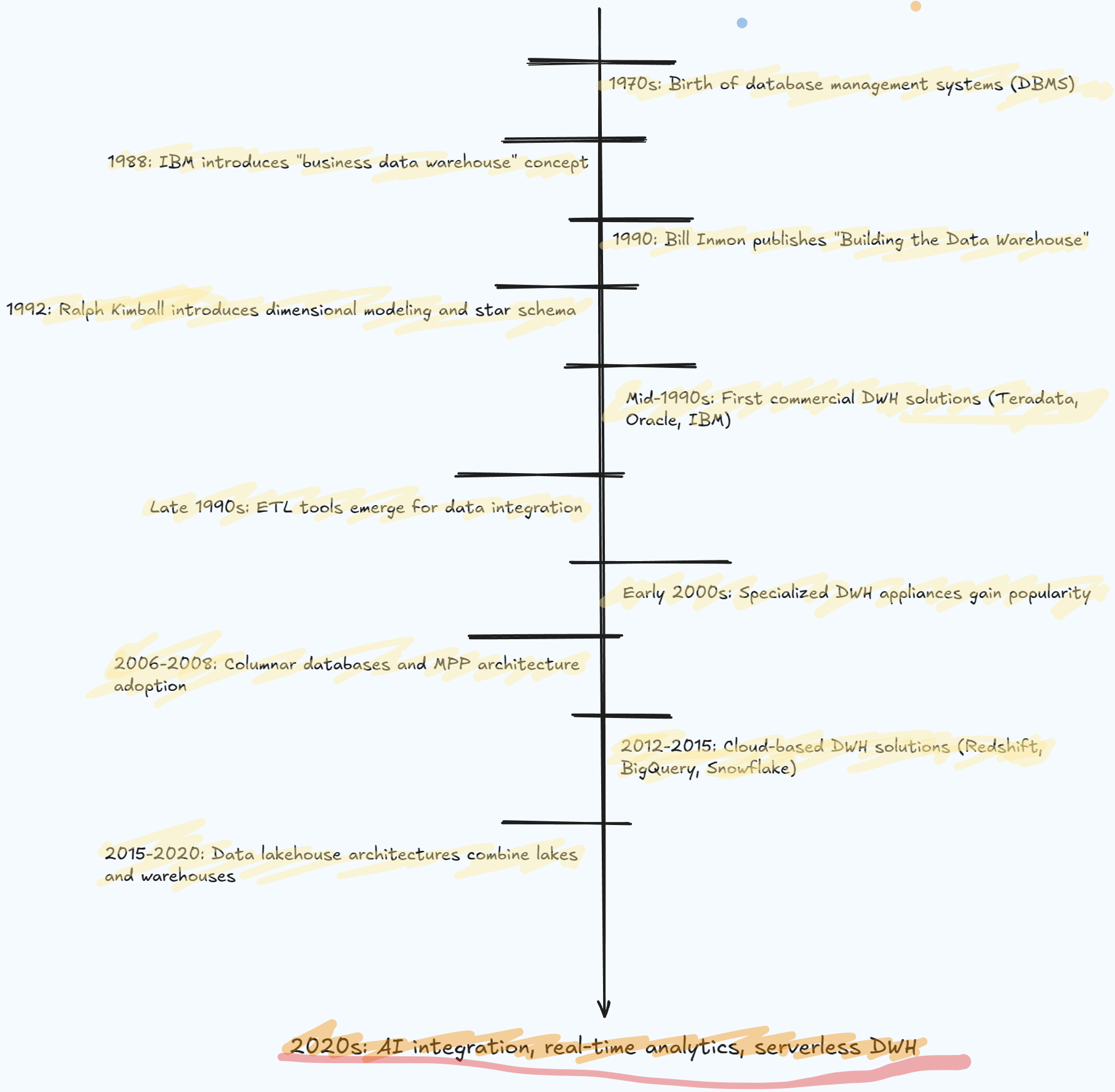
Data warehousing has undergone several major transformations since its inception in the late 1980s. Understanding this evolution provides crucial context for appreciating why open table formats represent such a significant leap forward.
The Traditional Data Warehouse Era
The first generation of data warehouses emerged as businesses needed a way to consolidate operational data for analytical purposes. These on-premises systems, dominated by vendors like Teradata, Oracle, and IBM, introduced the concept of storing data in specialized structures optimized for analytical queries rather than transaction processing. While revolutionary at the time, these traditional data warehouses came with significant limitations:
- Costly infrastructure: Organizations had to purchase and maintain expensive proprietary hardware.
- Rigid scaling: Adding capacity meant purchasing more physical servers and storage.
- Schema complexity: Changes to data models required careful planning and often resulted in downtime.
- Limited concurrency: Supporting many simultaneous users required significant hardware investments.
- Vendor lock-in: Proprietary formats and tools created dependency on specific vendors.
The Cloud Data Warehouse Revolution
Around 2010, cloud data warehouses like Amazon Redshift, Google BigQuery, and later ❄️ Snowflake revolutionized the market. These solutions addressed many of the limitations of on-premises systems:
- Elasticity: Resources could scale up or down based on demand.
- Pay-for-use: Organizations only paid for the storage and computation they consumed.
- Managed infrastructure: Cloud providers handled maintenance, upgrades, and availability.
- Improved concurrency: Better support for multiple simultaneous workloads.
This cloud shift represented a massive improvement, but fundamental challenges remained. Most importantly, these systems still maintained a separation between data lakes (where raw data lived) and data warehouses (where structured, transformed data resided for analysis), creating data silos and increasing complexity.
The Big Data Influence
Meanwhile, the big data movement introduced transformative technologies like Hadoop and Spark. Hadoop pioneered the distributed processing of massive datasets across clusters of commodity hardware, dramatically reducing infrastructure costs for large-scale data processing. While early Hadoop implementations faced performance challenges for interactive queries, Apache Spark emerged as a breakthrough technology offering both massive scalability and impressive performance through its in-memory processing capabilities.
These big data technologies picked up the pace at handling vast, diverse datasets but initially presented challenges for business users accustomed to the SQL-based (in contrast to Apache Spark declarative way of thinking) interfaces and optimized analytical capabilities of traditional data warehouses. Organizations often found themselves maintaining separate systems: Hadoop/Spark clusters for raw data processing and data engineering workloads, alongside traditional data warehouses for business intelligence and reporting use cases.
This bifurcated approach created friction in data pipelines and prevented organizations from fully capitalizing on their data assets, setting the stepping stone for solutions that could bridge these worlds.
Today’s Data Warehouse Challenges
Despite significant advances, today’s data warehouse landscape still faces critical challenges:
- Data duplication: Organizations maintain copies of data in multiple systems (operational databases, data lakes, and warehouses).
- ETL complexity: Moving data between systems requires complex extract, transform, load processes.
- Cost management: Cloud warehouses can become surprisingly expensive at scale.
- Limited flexibility: Supporting diverse workloads (SQL, machine learning, streaming) often requires different specialized systems.
- Data freshness: Traditional batch ETL processes create latency between when events occur and when they’re available for analysis.
These problems and challenges have set the bedrock for the next evolution: data warehouses built on open table formats. By addressing the fundamental architectural limitations of previous approaches, these new systems promise to unify data lakes and warehouses while delivering the performance, flexibility, and cost-effectiveness that modern data teams demand. In the next section, we’ll explore what open table formats are and why they’re so transformative for data warehousing.

Understanding Open Table Formats
Open table formats represent a fundamental shift in how analytical data is stored and managed. Rather than being locked into proprietary database engines, these formats provide standardized ways to organize data files in cloud storage while maintaining database-like capabilities. Let’s explore what makes them special and how they’re changing the data landscape.
What Are Open Table Formats?
At their core, open table formats are specifications for storing tabular data in files (typically Parquet, ORC, or Avro) with additional metadata that enables database-like functionality. Unlike traditional database storage engines, these formats:
- Store data in open, standardized file formats in cloud object storage (like S3, GCS, or ADLS)
- Maintain metadata about table schema, partitioning, and file locations
- Support ACID transactions (Atomicity, Consistency, Isolation, Durability)
- Enable schema evolution without data migration
- Provide time travel capabilities (accessing previous versions of data)
- Allow for concurrent reads and writes
Importantly, these formats are open-source, meaning no single vendor controls their development or implementation. This openness creates a vivid ecosystem of tools and systems that can read from and write to these formats.
Major Open Table Formats
Three open table formats have emerged as leaders in this space:
Apache Iceberg
Developed initially at Netflix and now an Apache project, Iceberg was designed to solve the scale problems faced when managing petabyte-sized datasets. Key features include:
- Hidden partitioning that decouples physical organization from queries
- Schema evolution with full type safety
- Time travel with snapshot isolation
- ACID transaction guarantees
- Optimized metadata handling for performance at scale
- Growing adoption in tools like Dremio, Snowflake, Databricks, and AWS Athena, recently AWS announced S3 tables
Delta Lake
Created by Databricks, Delta Lake brings reliability to data lakes with:
- ACID transactions on Parquet files
- Scalable metadata handling
- Time travel (data versioning)
- Schema enforcement and evolution
- Unified batch and streaming data processing
- Strong integration with Apache Spark
- An active open-source community
Apache Hudi
Originating at Uber, Hudi (Hadoop Upserts Deletes and Incrementals) focuses on:
- Incremental data processing and change data capture (CDC)
- Upsert capabilities (combining inserts and updates)
- Fine-grained record-level versioning
- Near real-time data ingestion
- Support for slowly changing dimensions
- Integration with various query engines
How Open Table Formats Differ from Traditional Storage
The difference between open table formats and traditional database storage engines is analogous to the difference between open document formats (like .docx or .pdf) and proprietary word processors. Traditional data warehouses tightly couple the storage format with the query engine, creating vendor lock-in. If you want to access your data, you must use that vendor’s tools and pay their prices.
Open table formats, in contrast, separate storage from computation. Your data lives in standard files in cloud storage, and metadata about those files is managed by the table format. This allows multiple engines (SQL query engines, Spark jobs, ML training systems) to read and write the same data without conversion or duplication.
This architectural shift has profound implications:
- Storage becomes commoditized: You can leverage inexpensive cloud object storage rather than specialized database storage.
- Engine flexibility: Different workloads can use different computation engines on the same data.
- No vendor lock-in: You can switch query engines or use multiple engines without migrating your data.
- Future-proofing: As new processing technologies emerge, they can be adopted without changing your data storage.
This fundamental decoupling of storage and computation is what enables the “lakehouse” architecture—combining the best aspects of data lakes (low-cost storage, schema flexibility) with the best of data warehouses (performance, reliability, ACID guarantees).
In the next section, we’ll explore the specific advantages this approach offers and why it’s compelling enough to potentially replace traditional data warehouses entirely.
Key Advantages of Open Table Format-Based DWHs
The combination of open table formats with modern query engines creates a powerful alternative to traditional data warehouses. Here are the key advantages driving this architectural shift:
Data Lake and Data Warehouse Convergence: The Lakehouse Architecture
Perhaps the most significant advantage is the elimination of the traditional divide between data lakes and data warehouses. The “lakehouse” architecture combines:
- The economics and flexibility of data lakes: Storing data in low-cost object storage with support for diverse data types and processing paradigms.
- The performance and reliability of data warehouses: ACID transactions, efficient query processing, and robust governance.
This convergence means organizations no longer need to maintain separate systems and complex ETL processes between them. Data can be ingested once and used for multiple purposes, from BI reporting to machine learning.
Time Travel and Versioning
Open table formats maintain a history of changes to your data:
- Query data as it existed at any point in time
- Roll back problematic changes when issues are discovered
- Reproduce historical analyses for compliance or audit purposes
- Implement slowly changing dimensions without complex ETL
This capability is not just a convenience—it’s essential for regulatory compliance, debugging data quality issues, and ensuring analytical reproducibility.
Cost Efficiency
The economics of open table format data warehouses are compelling:
- Storage efficiency: Pay only for the actual data stored, not for database-specific structures
- Compute optimization: Scale computation resources based on actual needs
- Elimination of data duplication: Store data once and use it for multiple purposes
- Reduced ETL: Simplify data pipelines by processing data in place
Schema Evolution Capabilities
In traditional data warehouses, schema changes often require painful migrations or downtime. Open table formats provide elegant solutions:
- Add, remove, or rename columns without rewriting data
- Change column types with compatibility checks
- Evolve nested structures gracefully
- Track schema history for reproducibility
ACID Transactions at Scale
Unlike traditional data lakes, open table formats provide true ACID guarantees:
- Atomicity: All changes in a transaction either succeed or fail together.
- Consistency: Data remains in a valid state, even if failures occur.
- Isolation: Concurrent transactions don’t interfere with each other.
- Durability: Committed changes survive system failures.
These properties ensure data reliability even with concurrent writers and complex transformations across petabyte-scale datasets.
5. Real-World Use Cases and Success Stories
The transition from traditional data warehouses to those based on open table formats isn’t just theoretical—many organizations have already made this shift and are reaping significant benefits. Let’s examine some real-world examples that demonstrate the practical advantages of this approach.
Netflix: Pioneering Scale with Apache Iceberg
Netflix was one of the earliest adopters of open table formats, with their data infrastructure team developing what would eventually become Apache Iceberg. Facing challenges with petabyte-scale datasets and billions of small files, Netflix needed a solution that could:
- Handle massive scale efficiently
- Support schema evolution without disruption
- Provide consistent performance as data grew
- Enable diverse workloads from the same data
By implementing Iceberg as their core data format, Netflix achieved:
- 70% reduction in metadata processing time for large tables
- Near-constant-time operations regardless of table size
- Simplified data engineering with automatic partitioning optimization
- Improved query performance through better file pruning
Their successful implementation has become a blueprint for other organizations dealing with large-scale data challenges.
Uber: Real-Time Analytics with Apache Hudi
Uber’s data needs are centered around real-time analytics on continuously updating data. They needed to:
- Ingest millions of events per second
- Update existing records efficiently (e.g., trip status changes)
- Support both batch and streaming use cases
- Maintain historical data for compliance and analytics
Their implementation of Apache Hudi (which they developed) delivered:
- Reduced latency from 24+ hours to under 30 minutes for data availability
- 10x reduction in storage costs through optimized file management
- Elimination of complex ETL pipelines between streaming and batch systems
- Improved data quality and consistency across analytical systems
Expedia: Unifying Analytics with Delta Lake
Expedia Group faced challenges with fragmented data across multiple systems and wanted to consolidate their architecture while improving performance. Their adoption of Delta Lake resulted in:
- 90% reduction in processing time for key analytical workloads
- Eliminated data silos by unifying data lakes and warehouses
- Enhanced data quality through schema enforcement and ACID transactions
- Accelerated machine learning initiatives by making data more accessible
ByteDance: Scaling with Open Table Formats
ByteDance, the company behind TikTok and other popular applications, processes enormous volumes of data for analytics and recommendation systems. Their adoption of open table formats has enabled:
- Efficient processing of 1,500+ petabytes of analytical data
- Support for 300,000+ daily jobs across various applications
- Reduced storage costs while improving query performance
- Simplified architecture by eliminating separate systems for different workloads
Airbnb: Improving Data Quality and Accessibility
Airbnb’s transition to open table formats focused on enhancing data quality and making data more accessible across the organization. Their implementation delivered:
- Improved data freshness from daily to hourly updates
- Enhanced data quality through schema enforcement and validation
- Reduced operational overhead by eliminating complex ETL processes
- Better support for diverse analytics needs from different teams
Performance Benchmarks: Traditional vs. Open Format Approaches
A growing body of performance benchmarks demonstrates the advantages of open table formats:
Query performance: Many implementations show comparable or better performance than traditional data warehouses for analytical queries, particularly as data scale increases.
Data ingestion: Open table formats typically show 2-5x improvements in data ingestion speeds, especially for update-heavy workloads.
Storage efficiency: Organizations typically report 30-60% storage cost reductions compared to traditional data warehouses, primarily due to better compression and elimination of duplicative storage.
Resource utilization: The ability to scale compute independently of storage leads to 40-70% improvements in overall resource efficiency in most implementations.
Business Problems Solved
Beyond the technical metrics, organizations adopting open table formats report solving key business challenges:
Real-time decision making: The reduced latency between data generation and availability enables more timely business decisions.
Unified analytics and AI Workloads: Breaking down silos between batch and streaming data, or between BI and ML workloads, creates a more cohesive analytical/data environment.
Data democratization: Making data more accessible to different tools and users increases the organization’s ability to derive value from data.
Cost predictability: The clearer separation of storage and compute costs makes budgeting more predictable and transparent.
Future-proofing: The open nature of these formats provides confidence that investments in data and analytics will remain valuable as technology evolves.
These real-world examples demonstrate that the advantages of open table formats aren’t just theoretical—they’re delivering multiple benefits to organizations across industries and at various scales. In the next section, we’ll explore practical strategies for implementing this approach in your own organization.
Conclusion
Open table formats represent a fundamental shift in data warehousing that addresses core limitations of traditional approaches. By decoupling storage from compute, providing ACID guarantees at scale, and supporting diverse workloads on the same data, they’re delivering significant benefits: reduced costs, improved performance, greater flexibility, and freedom from vendor lock-in.
The convergence of data lakes and warehouses into the “lakehouse” architecture eliminates costly data duplication and complex ETL processes while maintaining the performance and reliability businesses require.
Organizations that embrace this approach position themselves to adapt more quickly to changing needs and emerging technologies.
The question isn’t whether open table formats will replace traditional data warehouses, but how quickly the transition will happen.