
The 87-Millisecond Gap
Your database says it’s 10:00:00.000. The atomic clock in Colorado says it’s 10:00:00.087.
The difference that had been made? A melting glacier in Greenland, an earthquake in Chile, and a $2 quartz crystal vibrating inside your server.
Somewhere in that 87-millisecond gap, a $50,000 transaction just disappeared from your revenue report.
Here’s what happened: You processed the same Kafka topic twice. Same code, same data, same time range. First run reported $10.2M in transactions. Second run reported $11.4M. You were missing $1.2M worth of payments, and nobody noticed for three months.
The culprit wasn’t a bug in your code. It wasn’t a network failure or a corrupted file. It was time itself—or more specifically, three different versions of what “10:00:00” means across your distributed system.
Your application server thought a transaction happened at 10:00:00.050. Your Kafka broker recorded it at 09:59:59.970. Your Spark executor processed it at 10:00:00.120. Same transaction, three different timestamps, 150 milliseconds of spread. When you ran your five-minute window aggregation, the transaction fell into different buckets depending on which clock was telling the truth.
None of them were.
Today, we’re going to follow time from its birth in atomic clocks, through Earth’s chaotic rotation, past earthquakes and melting ice caps, into the crystal oscillator in your server, and finally into your database—where it arrives with the wrong value and makes your transactions disappear.
You’ll learn why your server can’t actually tell time, how planetary physics corrupts your timestamps, and what to do about it
⚛️ Part 1: Two Ways to Measure Time
The Tale of Two Clocks
Every computer has a fundamental problem: it needs to know what time it is, but it can’t afford the equipment that actually measures time accurately.
Let me show you the gap.
Atomic Clocks: The Truth
An atomic clock in Boulder, Colorado contains cesium-133 atoms. When you excite these atoms with microwave radiation at exactly the right frequency, they oscillate in a perfectly predictable way. Count exactly 9,192,631,770 oscillations, and exactly one second has passed.
This isn’t an approximation. This is the definition of a second. Since 1967, the international standard for time has been based on cesium atoms, not Earth’s rotation, not pendulums, not anything else.
The accuracy? Within one nanosecond. These clocks are so precise that if you started one at the beginning of the universe 13.8 billion years ago, it would be off by less than a second today.
The cost? $50,000 to $100,000 a piece .Sometimes much more.
Crystal Oscillators: Your Reality
Your server contains a quartz crystal about the size of a grain of rice. When you apply electricity, the crystal vibrates at 32,768 Hz—exactly 2^15 times per second, which makes it convenient for binary counters.

If you are interested in electronics and physics of the oscilators this link explains everything.
The crystal counts oscillations just like cesium atoms do. But quartz isn’t cesium. The vibration frequency changes with temperature. It drifts as the crystal ages. Manufacturing defects mean each crystal vibrates slightly differently.
The accuracy? Somewhere between 50 and 100 parts per million. That translates to 4-8 seconds of drift per day.
The cost? Fifty cents to two dollars.
The Gap
Here’s what this looks like in practice:
Atomic clock (NIST, Boulder): 10:00:00.000000000
Your server (thinks it's right): 10:00:00.087000000
Actual drift: 87 milliseconds
Your server has no idea it’s wrong. The crystal oscillator is counting vibrations and reporting timestamps with complete confidence. It just happens to be counting vibrations that are slightly faster or slower than they should be.
This is why every device needs Network Time Protocol. NTP’s entire job is to ask atomic clocks “what time is it?” and then correct your crystal oscillator’s drift. Your server does this every 64 to 1024 seconds, depending on how badly your crystal is drifting.
But here’s the problem: between NTP syncs, your clock is on its own. If your crystal drifts at 100 parts per million and you sync every 1000 seconds, you can accumulate up to 100 milliseconds of error between syncs.
And in a distributed system with dozens or hundreds of servers, each syncing at different times, each with crystals drifting at different rates?
You don’t have one version of “10:00:00.” You have dozens.
🌍 Part 2: Earth Isn’t a Clock
Why Planetary Physics Matters
Here’s where it gets interesting. We have atomic clocks that measure time with nanosecond precision. Problem solved, right?
Not quite. Because humanity decided that time should be synchronized with Earth’s rotation. When the sun is highest in the sky, we want it to be roughly noon. This seems reasonable until you realize Earth is a terrible clock.
Two Kinds of Time
There are actually two different time standards running in parallel:
TAI (International Atomic Time): Pure atomic time. It started in 1972 and has been counting cesium oscillations ever since. It never stops, never adjusts, never looks at Earth.
UTC (Coordinated Universal Time): Atomic time that’s been adjusted to match Earth’s rotation. It’s what your computer uses.
The gap between them? Thirty-seven seconds.
That gap exists because Earth’s rotation isn’t constant. And every time Earth speeds up or slows down enough, international timekeepers add or remove a “leap second” from UTC to keep it aligned with the planet.
Your distributed system runs on UTC. Which means your timestamps are tied to Earth’s rotation speed. Which means earthquakes, melting glaciers, tsunamis, and ocean tides directly affect your data pipeline.
What Changes Earth’s Rotation
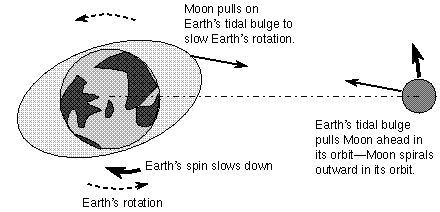
1. Tidal Friction (The Slow Death)
The Moon’s gravity pulls on Earth’s oceans, creating tides. As water sloshes around the planet, friction converts rotational energy into heat. Earth is constantly slowing down.
The rate? About 1.7 milliseconds per century.
This doesn’t sound like much until you realize it’s cumulative. Days are getting longer. In the age of dinosaurs, a day was about 23 hours. In 200 million years, a day will be 25 hours.
For timekeepers, this means we need to add leap seconds every few years to keep UTC aligned with Earth’s actual rotation.
2. Earthquakes (The Sudden Shifts)
When a massive earthquake strikes, it literally redistributes Earth’s mass. Rock moves. Continents shift. The planet’s moment of inertia changes.
Remember physics? When a figure skater pulls their arms in, they spin faster. Same principle. When an earthquake shifts mass toward Earth’s axis, rotation speeds up. When it shifts mass away, rotation slows down.
The 2011 Tōhoku earthquake in Japan (magnitude 9.0) moved so much mass that it shortened Earth’s days by 1.8 microseconds. The 2010 Chile earthquake (8.8) took off 1.26 microseconds. The 2004 Indian Ocean earthquake (9.1) shaved off 6.8 microseconds.
These aren’t theoretical calculations. Scientists measure these changes using Very Long Baseline Interferometry—radio telescopes positioned across continents that track Earth’s rotation by observing distant quasars.
3. Climate Change (The Gradual Redistribution)
Glaciers are melting. Ice that was concentrated at the poles is now flowing into the oceans, spreading that mass toward Earth’s equator.
This is like the figure skater extending their arms: rotation slows down.
The effect is small—microseconds per year—but it’s accelerating as ice melt accelerates. The Greenland ice sheet alone contains enough water to slow Earth’s rotation by roughly 0.6 milliseconds if it all melted.
 The picture is taken from the movie “Before the Flood” where they are showing simulation of the infuence of melting ice caps on earth streams and rotation.
The picture is taken from the movie “Before the Flood” where they are showing simulation of the infuence of melting ice caps on earth streams and rotation.
4. Atmospheric and Ocean Changes (The Daily Chaos)
High-altitude winds redistribute air mass. Ocean currents move water around. Even seasonal weather patterns affect rotation.
The variation? Up to 1-2 milliseconds per day.
Earth spins slightly faster in summer than in winter because atmospheric circulation patterns change. El Niño and La Niña events measurably affect rotation speed by shifting ocean water masses.
The Leap Second Problem
To keep UTC aligned with Earth’s messy rotation, the International Earth Rotation and Reference Systems Service (IERS) monitors the planet using GPS satellites, radio telescopes, and laser ranging. When the gap between atomic time and Earth time gets too large, they announce a leap second.
Here’s what a leap second looks like:
Normal time progression:
23:59:58 → 23:59:59 → 00:00:00 ✓
Positive leap second:
23:59:58 → 23:59:59 → 23:59:60 → 00:00:00
↑
Extra second inserted
Negative leap second (never used yet, but possible):
23:59:58 → 00:00:00
↑
Skip 23:59:59 entirely
Since 1972, we’ve added 37 leap seconds. We’ve never removed one, but as Earth’s rotation becomes less predictable due to climate change, we might need to.
And every time a leap second happens, systems break. Reddit went down in 2012. Cloudflare had an outage in 2017. Qantas airport check-in systems failed. Linux kernel bugs were triggered.
Why? Because your database suddenly sees the same second twice. Or time goes backwards. Or monotonic ordering assumptions break.
But here’s the thing: even without leap seconds, the problem exists. Between leap second adjustments, Earth’s rotation is still variable. Your NTP servers compensate by gradually “slewing” time—speeding up or slowing down your clock slightly to account for Earth’s current rotation speed.
You’re not just syncing to atomic clocks. You’re syncing to a moving target that’s affected by earthquakes you didn’t know happened and glaciers melting thousands of miles away.
📡 Part 3: The Synchronization Dance
How NTP Bridges Two Worlds
So we have atomic clocks measuring time perfectly, and we have Earth rotating unpredictably, and we have your server with a cheap crystal that drifts by seconds per day.
Network Time Protocol is what tries to make sense of this mess.

The NTP Hierarchy
NTP organizes time sources into layers called “strata”:
Stratum 0: Atomic clocks, GPS satellites
↓ directly connected
Stratum 1: Servers with direct connections to atomic clocks
↓ synchronized over network
Stratum 2: Servers that sync from Stratum 1 (probably your infrastructure)
↓
Stratum 3+: Further removed from the source
The further you get from Stratum 0, the more uncertainty accumulates. Network latency, processing delays, and multiple hops all add jitter.
Your typical data center server is probably Stratum 2 or 3, syncing from public NTP pool servers or internal time servers. The synchronization happens every 64 to 1024 seconds, depending on how much your clock has been drifting.
What Actually Happens During Sync
Your server sends a packet to an NTP server: “What time is it?”
The NTP server responds with four timestamps:
- When your request left your machine
- When it arrived at the NTP server
- When the NTP response left the server
- When it arrived back at your machine
From these four timestamps, NTP calculates two things:
- Offset: How wrong your clock is
- Round-trip delay: How long the network took
If your offset is small (a few milliseconds), NTP gradually adjusts your clock by making it tick slightly faster or slower. This is called “slewing.” It prevents time from jumping backwards, which would break applications that assume time is monotonic.
If your offset is large (more than 128 milliseconds), NTP gives up on slewing and just jumps your clock to the correct time. This is called “stepping.” It’s fast but dangerous—suddenly timestamps can go backwards.
The problem? Network latency adds uncertainty.
On a local network: ±0.1 to 1 millisecond of uncertainty Over the internet: ±10 to 50 milliseconds of uncertainty On congested networks: ±100+ milliseconds of uncertainty
So even after syncing, your clock isn’t perfectly accurate. It’s “probably within 10-50 milliseconds of correct, assuming the network behaved normally.”
Between Syncs: You’re On Your Own
Here’s the bigger problem: NTP doesn’t sync continuously. It syncs every 64 to 1024 seconds (roughly 1 to 17 minutes) depending on your clock’s stability.
Between syncs, your crystal oscillator is drifting.
Let’s do the math:
- Your crystal drifts at 100 parts per million (ppm is a ratio: for every 1 million seconds, you’re off by 100 seconds—that’s about 8.6 seconds per day)
- Time since last sync: 1000 seconds (about 16 minutes)
- Accumulated drift: 1000 × 100 / 1,000,000 = 0.1 seconds = 100 milliseconds
You could be 100 milliseconds off and not know it until the next sync.
The Distributed System Problem
Now imagine you have three servers processing the same Kafka topic:
Server A:
- Last NTP sync: 30 seconds ago
- Current drift: +15 milliseconds
- Clock reads: 10:00:00.015
Server B:
- Last NTP sync: 10 minutes ago
- Current drift: -60 milliseconds
- Clock reads: 09:59:59.940
Server C:
- Last NTP sync: 45 minutes ago (missed several syncs due to network issues)
- Current drift: +200 milliseconds
- Clock reads: 10:00:00.200
All three servers think they’re reading the correct time. All three would report their timestamps with confidence. But they’re spread across 260 milliseconds.
An event occurs at “true time” 10:00:00.000. How does each server timestamp it?
Same event. Three different timestamps. 260 milliseconds of spread.
Now you run a five-minute tumbling window aggregation. Windows are defined as:
[09:55:00.000 - 10:00:00.000)[10:00:00.000 - 10:05:00.000)[10:05:00.000 - 10:10:00.000)
Which window does the event belong to?
Server A says: second window Server B says: first window Server C says: second window
If you’re doing distributed processing with Spark or Flink, different executors might process this event differently depending on which timestamp they see. You might count it twice. You might not count it at all. You might count it in the wrong window.
And here’s the worst part: this isn’t a rare edge case. This is happening constantly, to thousands of events, across your entire data pipeline. Most of the time, the drift is small enough that you don’t notice. But sometimes—during network issues, after server restarts, during leap second adjustments—the drift gets large enough to corrupt your aggregations.
💥 Part 4: The Bermuda Triangle for Transactions
Where $50,000 Goes to Die
There’s a place in your distributed system where transactions disappear. Not because of bugs. Not because of network failures. Not because of corrupted data.
They vanish in the gap between three clocks that can’t agree on what “now” means.
The Disappearing Act:
A customer clicks “Buy” on a $50,000 enterprise software license. The payment processes successfully. The database writes the record. The event lands in Kafka. Everything works.
Then you run your revenue aggregation. The transaction isn’t there.
You check the raw data. It exists. You check your code. No bugs. You check your filters. All correct. You run the aggregation again. Still missing.
Three months later, you run the same job on the same data. The transaction appears. $50,000 that didn’t exist suddenly exists.
Welcome to the Bermuda Triangle of distributed systems: the five-minute window boundary.
The Crime Scene:
Let’s reconstruct what happened. The actual moment of purchase—according to an atomic clock nobody in your system can see—was 09:59:59.998. Two milliseconds before the window closes.
Your pipeline uses five-minute tumbling windows:
Window 1: [09:55:00.000 - 10:00:00.000)
Window 2: [10:00:00.000 - 10:05:00.000)
Window 3: [10:05:00.000 - 10:10:00.000)
Simple boundaries. Clear rules. Should be deterministic.
But three servers witnessed this transaction, and they can’t agree when it happened.
The Three Witnesses:
Witness A (Application Server):
“I saw it at 10:00:00.048. Definitely in the 10:00-10:05 window.”
Witness B (Kafka Broker):
“No, I recorded it at 09:59:59.968. That’s in the 09:55-10:00 window.”
Witness C (Spark Executor):
“You’re both wrong. My timestamp says 10:00:00.148. Second window, clearly.”
All three are certain. All three are wrong. The transaction happened at 09:59:59.998, but none of them know that.
The Interrogation:
Why do three servers see three different times?
Server A’s confession:
- Last NTP sync: 2 minutes ago
- Crystal oscillator drift: +50 milliseconds and counting
- “My clock said 10:00:00.048 when the event arrived. That’s what I recorded.”
Server B’s confession:
- Last NTP sync: 30 seconds ago
- Crystal drift: -30 milliseconds (running slow)
- “When I received the message, my clock showed 09:59:59.968. I timestamp everything as it arrives.”
Server C’s confession:
- Last NTP sync: 20 minutes ago (missed several attempts due to network congestion)
- Crystal drift: +150 milliseconds and climbing
- “By the time I processed it, my clock read 10:00:00.148. Not my fault if everyone else is slow.”
Same event. Same physical moment. 180 milliseconds of spread across three timestamps.
The Core Problem:
Here’s what we’ve learned: Wall clock time is fundamentally unreliable for distributed processing. It’s tied to Earth’s rotation, corrected by leap seconds, synchronized through unreliable networks, and measured by cheap crystals that drift constantly.
Every time you use wall clock time for event ordering, window boundaries, or session calculations, you’re making a dangerous assumption: that all clocks agree on what “now” means. They don’t. They can’t. They never will.
What you need instead is a clock that doesn’t care about Earth’s rotation. A clock that never adjusts for leap seconds. A clock that never goes backwards. A clock that only moves forward, monotonically, at a consistent rate—even if that rate doesn’t match atomic time.
This is called a monotonic clock. It doesn’t tell you the time of day. It just tells you: X nanoseconds have elapsed since some arbitrary starting point. No drift corrections. No NTP adjustments. No planetary physics.
For event ordering, you don’t need to know if something happened at “10:00:00 UTC.” You just need to know: did event A happen before event B? A monotonic clock answers that question reliably. Wall clock time doesn’t.
The solution isn’t better NTP configuration or more accurate crystals. The solution is to stop using wall clock time for anything that requires correctness.
✅ Part 5: The Solution
Stop Trusting Wall Clocks
The fix isn’t complicated. It just requires accepting one truth: wall clock time lies.
Here’s what to do instead.
1. Use Event Time, Not Processing Time
Timestamp events when they happen, not when your server processes them.
| |
Assign the timestamp at the source—the moment the user clicks, the moment the sensor fires, the moment the transaction commits. Lock it in. Never change it.
Your Kafka broker might receive it 50ms later. Your Spark job might process it 2 minutes later. Doesn’t matter. The event time stays fixed.
2. Accept That Data Arrives Late
Even with event time, data doesn’t arrive in perfect order. Networks have delays. Systems retry. Batches get reprocessed.
Use watermarks to handle this:
This says: “Accept events up to 5 minutes late. After that, close the window.”
How big should your watermark be? Measure your actual latency. Look at your P99. Add a buffer. Monitor how much data arrives after the watermark and adjust.
3. Use Sequence Numbers for Ordering
Wall clocks don’t tell you which event came first. Sequence numbers do.
| |
This is the Snowflake ID pattern (Twitter invented it). The ID embeds rough time information but adds a sequence number that guarantees order even if multiple events happen in the same millisecond on the same machine.
4. Monitor Clock Drift
You can’t eliminate drift, but you can know when it’s dangerous.
| |
Set alerts:
- Warning at 50ms
- Critical at 100ms
- Emergency shutdown at 500ms
If a server’s clock drifts beyond your tolerance, stop using it for time-sensitive operations until it resyncs.
5. Make Operations Idempotent
Even with perfect timestamps, distributed systems duplicate events. Networks retry. Kafka rebalances. Jobs restart.
Design so that processing the same event twice produces the same result. Use unique event IDs to check if you’ve already processed a payment or transaction. If the payment ID already exists in your system, skip it. Make state changes atomic—check, update, and record in a single operation so you can’t partially process something twice.
This means moving away from “subtract amount from balance” logic toward “record this specific payment with this specific ID and update accordingly.” The ID becomes your source of truth, not the timestamp.
🎯 Conclusion
What’s Actually Happening:
Your server’s $2 quartz crystal drifts 8 seconds per day. NTP syncs it to atomic clocks adjusted for Earth’s rotation which earthquakes and melting glaciers change. Between syncs: 50-200ms drift. Across distributed servers: dozens of conflicting versions of “10:00:00.”
The Damage:
Transactions disappear into window boundaries. Revenue calculations break. Event ordering fails. Your $50,000 transaction vanishes.
The Fix:
Stop using wall clock time for correctness. Use event time, watermarks, sequence IDs, and idempotent operations. Wall clock time is for logging only—never for deciding which bucket holds your data.